
NEWS, EDITORIALS, REFERENCE
Image File Formats
The free software update v1.04 of C64 OS was released last month, June 2023. I like to give titles to the releases that capture the most important features of the release. I decided to call 1.04 the Multimedia Release.
The reason for calling it a Multimedia release is because it has 4 main changes related to graphics, animation and sound. Let me briefly touch on these 4 changes, and then we'll hop into the main point of this weblog post, which is to discuss Commodore 64 image file formats, including two new ones.
1) New video modes in splitscreen and fullscreen
From v1.0, C64 OS supports an adjustable raster-split which is referred to as splitscreen mode. It's built into the OS at the KERNAL level, with some help from a shared library called gfx.lib. The only reason for the gfx.lib is because if any Application doesn't need to use splitscreen mode, it's nice for it to reclaim some of that memory, and so some of the code that implements splitscreen which was originally in the KERNAL during the pre-release betas got moved to a shared library that could be loaded by those Applications that need it.
In addition to the splitscreen mode, there is also a fullscreen graphics mode. The two features are essentially the same thing; any Application that loads the gfx.lib and provides it with the pointers and configuration for the graphics data automatically gains support for both fullscreen and splitscreen modes.
Starting in v1.04, the gfx.lib and KERNAL have been updated to support all native VIC-II video modes. Prior to this update, only HiRes bitmap and MultiColor bitmap modes were available in split- and fullscreen graphics. Now, C64 OS supports HiRes character mode, MultiColor character mode, and Extended Background Color character mode, and each supports a custom character set. This opens the door for viewing PETSCII graphics which are very popular these days. Also most games are in a character mode with a custom tileset/characterset and this allows us either to view screen grabs of those games, but also makes it possible to implement games for C64 OS itself using those modes.
2) New image datatype loaders
One nice benefit of being able to view character modes in splitscreen and fullscreen is, at last, the ability to view C64 OS screenshots from within C64 OS. That seems like an obvious one. Before v1.04, you could take screenshots, but to view the screenshots you had to drop to BASIC and use the petsciiview tool.
New image datatype loaders have been added to C64 OS giving the Image Viewer Application access to a wider range of file formats including new character modes. A datatype loader exists now for the screenshot format, allowing us to double-click screenshots in File Manager and view them with Image Viewer. The screenshot format itself was updated to v2, and that's something that we'll talk about later in this post.
While I was on the kick of support for character modes, I discovered that the wonderful PETSCII Bots by Cal Skuthorpe had been released as a bundle with over 2400 individual image files on CSDB, so I wrote an image loader for those. And we'll talk about those later in this post too.
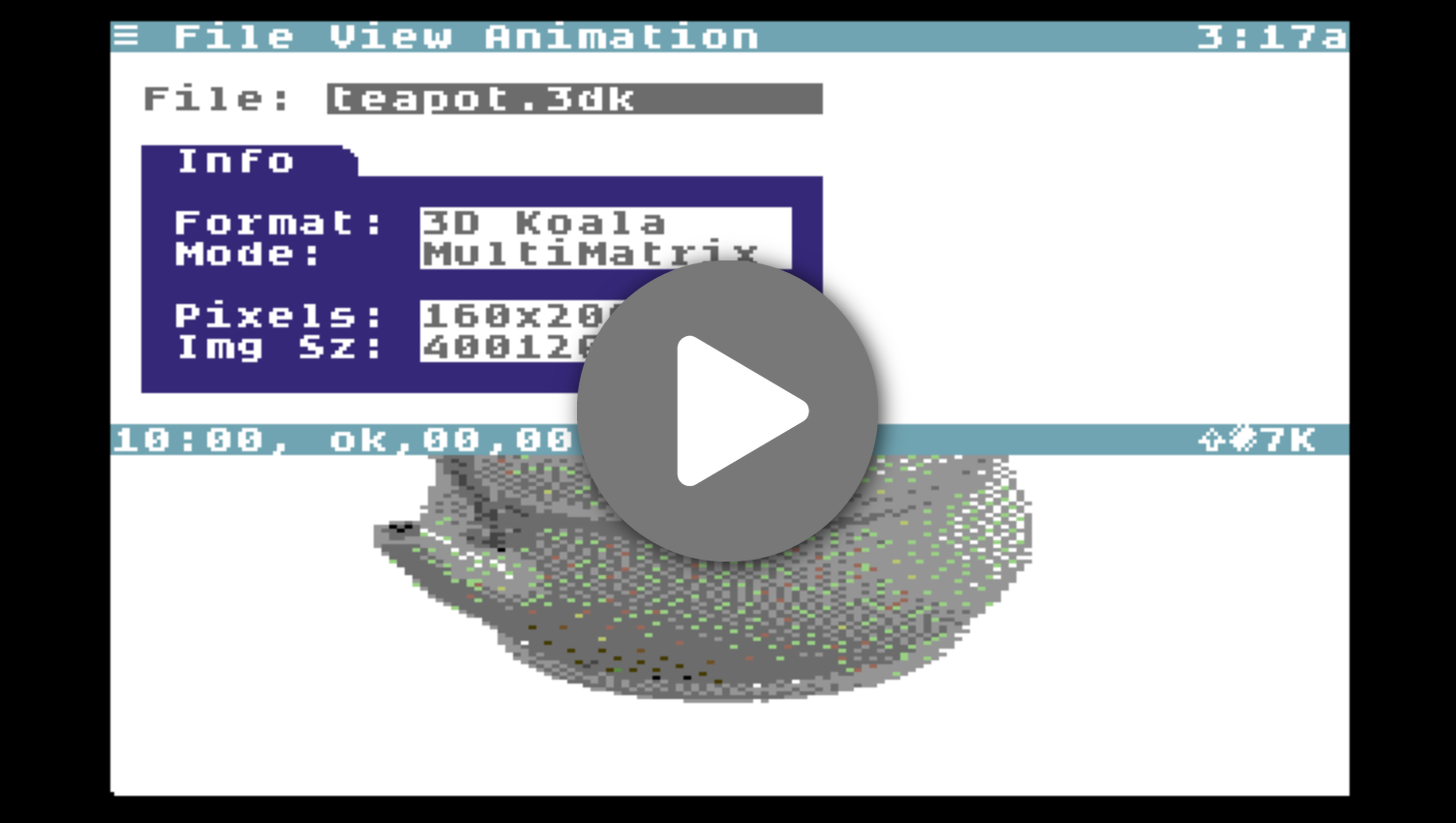
Additionally, I made two more image datatype loaders. One is for a simple but limited file format for matrix images. I showed these early on, on Twitter. You can see a brief sample of what that looks like below. You can also see that Image Viewer lists its format as "3D Koala" and its mode as "MultiMatrix". We'll talk about this later.
The other new datatype loader I created is much more ambitious. It is for an entirely new graphics container format called "Commodore Grafix" or CGFX for short (with a standard file extension of CGX.) We're going to talk about this a lot in this blog post, but for now it takes us to point #3 of why v1.04 was called the MultiMedia Release.
3) Panoramas, 3D matrix images, and animations
We'll get into the juicy details of how the new CGFX format supports multi-frame images, and the metadata for how the frames relate to each other, but here I'll just tell you what they bring to C64 OS.
A file format that holds data is one thing, but you also need software to view the data. There is a new image datatype loader for CGFX files, that corresponds with updates to the Image Viewer Application that has support for many (though not all) of the features that can be represented by CGFX. Besides just still images—single frames—in all of the native VIC-II video modes, there are three distinct uses for multi-frame images.
Panoramas are a series of horizontally aligned partially overlapping frames that when strung together form a single image that is much wider than the C64's screen. Panoramic photos taken on a smart phone can easily be chopped up into discrete overlapping frames that can be packed into a CGFX file. When opened in Image Viewer, the user can use the mouse to drag the image to pan left and right through the whole scene. A special left-right double-arrow mouse pointer gives you a hint that this image is a panorama.
3D Matrix Images are a matrix of image frames, rows and columns, where each frame shows a different angle on a 3D object. The earlier, more primitive 3D Koala format supports only a fixed matrix size of 5 rows and 8 columns, in MultiColor mode. CGFX supports variable matrix sizes, options for either horizontal wrap-around or vertical wrap-around, and different video modes. When viewed in Image Viewer you get a 4-directional mouse pointer to indicate that you can drag in all directions to spin and tilt the object.
Animations are a linear series of frames, not entirely unlike a panorama in structure, but each frame is a frame of animation. The format supports some of the features of animated GIFs, such as framerate, play count, and loop style. The format supports up to 256 frames, with a maximum framerate of 10 frames per second.
While an animation is paused, it can be interacted with much like a panorama, letting you scrub forwards and backwards through the frames. In the example below, of the rotating Earth, this works really well. You can watch the Earth rotating as an animation, but you can pause the playback and freely rotate the Earth in either direction with the mouse.
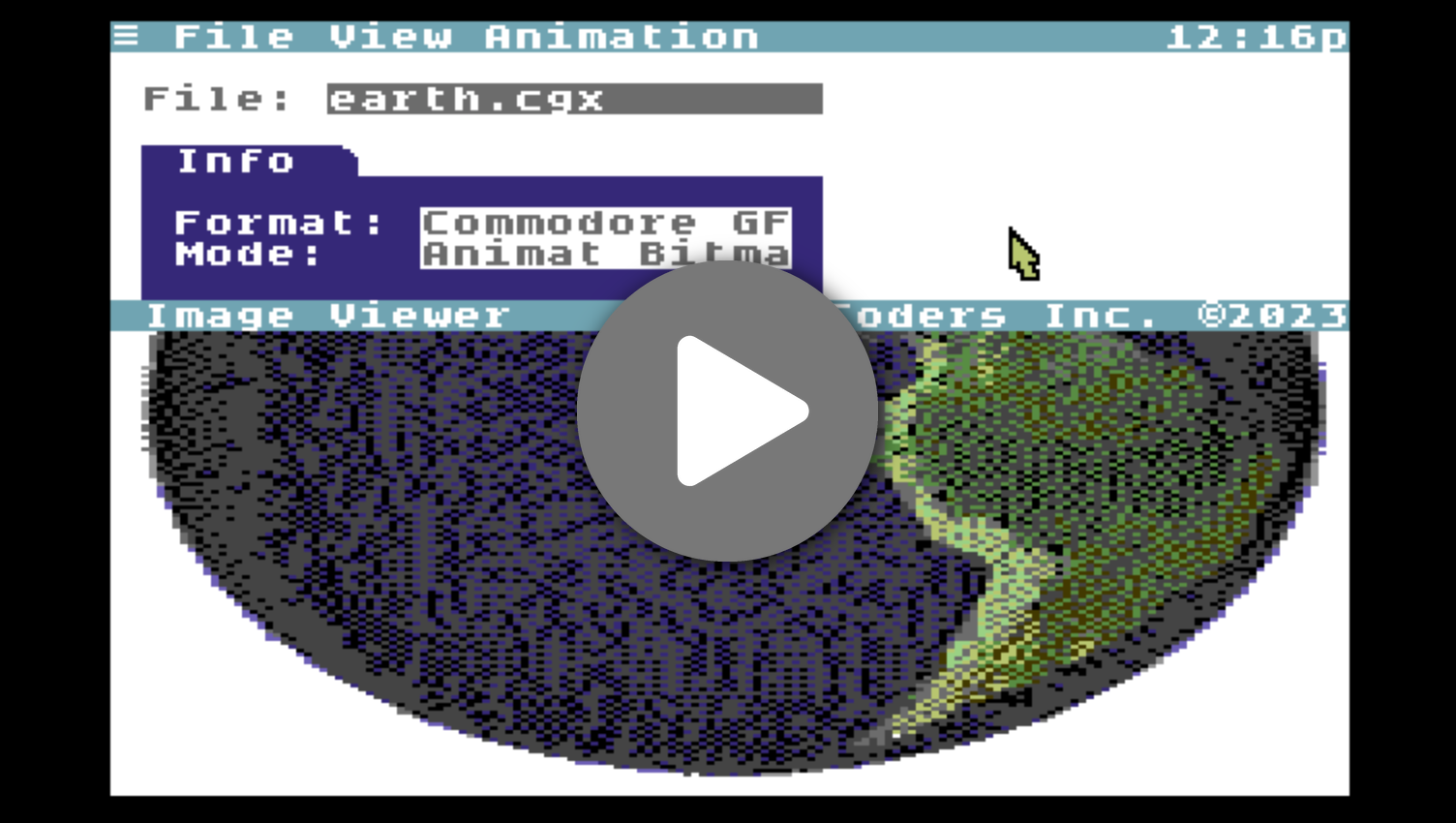
Aspect ratio
In the image above, the Earth looks wide and squat. However, when viewed on a C64, it looks much more round. That is because while a C64's screen is square, it has a horizontal resolution of 320 pixels but a vertical resolution of only 200 pixels. This trait of the real hardware makes individual pixels taller than they are wide. And it makes the squat Earth shown above look more round.
Collectively, these features make for some pretty cool MultiMedia interactions on the C64. Of course, the multi-frame images require a 17xx-compatible REU. But it has always been my goal for C64 OS to add value to expansion hardware. More software support for the REU gives people more reason to buy one, which gives more developers reason to support them, in a virtuous cycle.
Custom Boot Screens
A small aside, but another nice feature that contributes to the MultiMedia theme of v1.04; Image Viewer can save any currently visible frame (in HiRes or MultiColor bitmap mode) to be used as a custom boot screen. This lets you extract still frames from a panorama, 3D matrix, or animation to use as your boot screen. Very cool.
You can also use it to save any other still image in any HiRes or MultiColor file format, for which C64 OS has a datatype loader, to be used as a custom boot screen. Slick.
4) SID Preview
So far we've only talked about new graphics features, new image datatype loaders, animations and interactive image matrices. But v1.04 of C64 OS also adds the SID Preview Utility.
A library called sidplay.lib was available in C64 OS starting in v1.0, but the only thing that used it was the timer expiry in the Time Utility. It loads and plays the SID of your choice from //os/settings/:timer.sid. You can plop any (suitable/compatible) PSID in the settings directory and call it timer.sid, and that's the file that gets played when the timer expires. Pretty cool, but not a general purpose SID player.
In the future I'll probably work on a more complete SID playing Application, one that helps you organize a library of SID tunes, that helps you navigate a sizeable collection, built playlists, etc. But for now, 1.04 adds SID Preview. It lets you open PSID files from File Manager, shows the title, author and release metadata, lets you cycle through the various embedded tunes and play them.

SID Preview Utility
The only catch is that SID files are not written to play from arbitrary places in memory with arbitrary use of Zero Page, rather, each SID is hard-coded to play from a very specific place in memory and to use a very specific set of Zero Page addresses. This is okay when a game or demo is written to collaborate with its own SID music, or with a player (like SIDPlay64) that tries its damndest to get out of the way (without always being successful.) But it makes it very challenging to be integrated into an operating system. Software and components written for C64 OS are written explicitly with the aim to cooperate with other system components. But SID files, not so much.
To overcome this challenge, I've pumped almost the entire HVSC (High Voltage SID Collection) through sidreloc, by LFT, with relocation parameters that guarantee the resulting SID to be compatible with C64 OS. Not every SID can be successfully limited to the relocation parameters, but a great many can. It has also been my long-term goal to provide a suite of webservices to help C64 OS interact with the wider world. One of those services is a relocated SID search service. It can be found at: http://services.c64os.com/about And its backend database houses over 34,000 SID tunes that are compatible with C64 OS. All of the tunes available in this database can be played using SID Preview.
So those are some of the major new features in C64 OS v1.04, and the reason why it earned the title of MultiMedia Release. Now let's get into a discussion of what some of these new image file formats are all about.
What is an Image File Format... on the C64?
Let's start at the very beginning. A file format is a file whose contents are structured in a known, predictable way, that allows some other software to make use of its contents. This is a pretty basic concept, but in the land of the Commodore 64, it is remarkably wild-west.
Nominally, a file with a CBM File Type of PRG is supposed to be a program. That three-letter code, PRG, is kinda, sort of, a little bit like a file extension, but in practice not really. What it declares is that the data on the disk is sequential, and that the first 2 bytes of that data stream represent a memory address whither the remaining data ought to be loaded. So, it's kind of like a file format, but it's very primitive. If the file is a program, at the very least it puts the program's code into memory where it needs to be located in order to run properly. So far so good.
The problem is, there are lots of non-program files (i.e., files that can't just be directly executed) that also use the PRG file type. I'll use one example to illustrate this point, because it also happens to be directly relevant to the question of what an image file format is on the C64. Koala image files, those that can be loaded and saved as image data files by the Koala Paint program, use the PRG file type with a load address of $6000.
The KERNAL ROM's load routine is itself quite simple. It coordinates with the drive (the storage device, not just the 1541, but all standard IEC-based C64 storage devices) by opening the file on the drive's channel 0. Channel 0 is dedicated for loading binary data, and the drive returns an error if the file opened on that channel is not of PRG-type. Otherwise, the file data is streamed to the C64, but the KERNAL reads the first two bytes, uses them to set the starting address for the rest of the data and then proceeds to plunk each new byte read into memory starting at the start address. And that's it!
So why do Koala Paint data files have a CBM file type of PRG and a load address of $6000? It's because the VIC-II shares memory with the CPU. The CPU can see 4 banks of 16KB each. The VIC-II can see 1 bank of 16KB at a time, and some bits on CIA 2 control which of the 4 main banks is the one the VIC-II can see. The banks, thus, start at $0000 (the default bank on power up), $4000, $8000, or $C000. Within a 16KB video bank, there are precisely two halves out of which the VIC-II is capable of displaying a full screen bitmap image, which is just shy of 8KB. Therefore, in the bank starting at $4000, there are two 8KB bitmap-aligned ranges: $4000 to $5FFF or $6000 to $7FFF. Well, lo and behold, the $6000 load address of a Koala image file corresponds precisely with a possible VIC-II bitmap bank.
The only problem is that for the VIC-II to display a MultiColor bitmap, it also has to put some color data into screen matrix memory, which is configurably locatable within the same 16KB video bank as the bitmap data, plus it has to put some color data into the static color RAM chip. Unfortunately those two areas are not perfectly contiguous with the end of the 8000 bytes (slightly less than 8KB) of bitmap data. There are different ways to handle this, but what Koala does is it lets the KERNAL load the file (10001 bytes) from $6000 up to $8710. The bulk of the data, the first ~80% is in the right place already, and then it uses a short routine to move the final 2001 bytes to wherever they need to be.
What IS the Koala image file format?We know how it works, but what does this actually say about what the Koala image file format is? The data is structured in a way that is already hardware-format dependent. With a load address that is hardware-address dependent, putting much of the data exactly where the VIC-II needs it, just to move the small amount of data necessary, which is also hardware-format dependent, to a slightly different hardware-address dependent location. Whoa.
I've talked about this before in other blog posts, but it bears repeating. While this kind of thing is very common on the Commodore 64, it is totally unlike what we think of as a file format on other (more modern) computer platforms. It's not just the Koala format, almost all of the many native-mode C64 image file formats do something similar.
How are File Formats identified?
This is another place where the C64 began way out in the middle of the wild west, when it made little contact with the wider world.
Tapes and cartridges? No issue.The situation, in part, is that in the earliest days of Commodore computers software was loaded either from tape or cartridge. Working with files on tape is unbelievably onerous. I did it with my VIC 20 for the first few years of my childhood computing, but it requires a huge amount of manual and mechanical organization. What the file is named is the least of your worries. What matters is how long the file is, and where you can find space on a cassette to save the file on a continuous segment of tape, without accidentally plowing over previously saved data.
Cartridges are even less file-oriented. You plug the cartridge in and data—program code and content—are already mapped into fixed memory ranges ready to be used. Asking how you should best manage the identification of your different file formats on a computer that is primarily cartridge driven, is like asking how you manage file type identification on your Nintendo Entertainment System; the two just don't have anything to do with each other.
Low capacity floppies? The issue half arises.When you have a disk drive on your Commodore 64, things become a little more modern and the issue starts to make a little more sense. How should you name your data files when you save them? Names start to matter, because the non-linear storage of a disk makes it a snap to save multiple files to the same disk. You also have a directory that lists files by name, and files can be opened in any order from a disk. You just have to specify what filename you want to open. (This could be done on a tape too, but unless you wanted to wait around all day, it was more common to write the counter number on the cassette sleeve of where a program started.)
But it doesn't fully awaken the issue, because disks are so small that it was very rare indeed that you would have a single disk holding multiple data-file-using programs, plus multiple data files belonging to different programs. Often there was only enough room for the program on one disk and you had to store its data files on a different disk. In which case, you're back to manually managing files by disk. How the files are named, to identify their type, is almost completely irrelevant when you write "Fleet System II - Data Files" on the label sticker of the disk. Fleet System II was the first word processor I ever used, by the way. And its data files aren't just text, they contain special formatting codes specific to that word processor.
Mass storage (HD, CF, SD) devices? The issue becomes relevant.Things really start to matter when you upgrade from a disk drive to a mass storage device. I got my first mass storage device around 1994, a 40 MB CMD HD. And shortly thereafter I got a 16MB RamLink, and a few short years after that I upgrade the CMD HD to a 1GB mechanism and then got an IDE64 also probably with a 1GB mechanism.
That's when you start putting all of your Commodore 64 software on the same storage device. And you start storing all of your data files in subdirectories on the same device (with some categorical division by partitions.) It's still not entirely important to correctly identify your data files by type, because many software packages don't know anything about subdirectories, and so often you just have a large directory in which you can store both the program and all of its data files. And then you can have a different subdirectory with a different program and all of its data files. The types of the files are roughly identifiable by what program they are stored most proximate to in the file system.
In this situation, although you're using a mass storage device, it's as though each subdirectory is a large floppy disk. The island-like isolation of disks gets carried over to isolation between subdirectories. The majority of C64 software, one might argue, never left this stage.
The roles and risks of operating systemsAt least half the point of an operating system is to unify the environment, to allow you to work with your files and their Applications more easily, and to break down the walls of isolation between them.
The first operating system I used in earnest on the C64 was GEOS. GEOS 1.2, 1.3 and 2.0 was still quite disk bound, and so it was common to have GeoWrite and a couple of GeoWrite documents on one disk. And then GeoPublish and some GeoPub docs on a different disk, etc. Eventually I became a Wheels user, which makes using GEOS applications and documents from a CMD HD much more practical. Suddenly it was common to have many Desk Accessories and several Applications all in a system directory that was shared by many different subdirectories for documents.
GEOS, copying from the early Macs, let you double-click a document file and it would open in the appropriate application. Double-click a GEOPaint document and it finds GEOPaint and opens it. The open file picker dialog is skipped and the document opens right away. So, how does GEOS do this? It actually does it in a way that is reminiscent of the Macintosh. First, the file is of type USR, then the directory entry has a pointer to the first data sector, but it uses another pointer (I believe it's one of the pointers reserved for REL files, and so not used for USR files) to point at a side-sector that holds file metadata. I think there is a GEOS-type byte right in the directory entry too. A single type byte provides up to 256 possible types. The first few were statically allocated to different GEOS file types, such as fonts, applications, desk accessories, clippings, specific document types, etc.
There is a problem with this though.1 Just like in the classic Mac era, the Macintosh had to have a custom file system that supported its data and resource forks. This was fine for sharing files by floppy disk between different Macs, but it was a huge pain for sharing files with non-Macintosh computers. The problem got exacerbated when computers of different types started sharing the same networks. Macintosh files had to be compressed with some kind of Mac-file-system-aware conversion, such as StuffIt or BinHex.
GEOS files have long suffered the same problem. In order to move them through the internet, or transfer them via a PC, they have to first be converted using the GEOS Convert application, which serializes all their weird stuff into regular files. It's worse than that, even regular Commodore 64 file-copy utilities generally know nothing about the GEOS format and are unable to copy GEOS files, even on the very same Commodore 64 that created those files! GEOS files behave like foreign entities—even on the C64—to almost everything outside the GEOS environment.
Not to belabor the point, but those extra directory bytes (the REL pointers that got used for other things) are not accessible from the directory without performing block reads from the device, manipulating them manually and writing back to the disk with block writes. This made it very difficult for GEOS files to live on devices that do not closely mimic the original CBM file system. I.e., IDE64 and SD2IEC.
The move to simpler data streams, and simpler representationThe Macintosh, when it switched up to Mac OS X, eventually abandoned resource forks in favor of directory-based bundles, and type and creator codes got smashed together into filename extensions.
For years, Mac users bewailed the loss of important functionality when creator codes went away. (Eventually the functionality of creator codes has been restored in the form of extended attributes. And the extended attributes can even be retained by special ZIP format extensions when they're zipped on a Mac and later unzipped by another Mac.) Nonetheless, the creator code was always less important than the type code. And on today's bleeding edge Macs, a file's type is identified with a simple extension on the end of the filename. And guess what? Every file system stores files with a filename.
So what was once a file-system-specific feature, with a resource fork that could contain type and creator codes, and other custom metadata, has been simplified to a single data stream with a filename. The data and type information now have no trouble traveling with the file as it journeys through different networks, OSes, and file systems.
The upshot for the Commodore 64 in modern timesIt may seem like I have taken a circuitous route to saying, "Files on the C64 should have a filename extension to indicate the datatype." However, the argument needs to be made, because we are still in a world where that is not done and apparently it's not even obvious why it should be done.
Let me give you an example, and then we'll use that example to explain something about datatypes, file formats and datatype loaders. On April 1st, 2023, (no practical joke intended,) a collection of PETSCII BOTS by Cal Skuthorpe was released on CSDB. The collection comes with a custom viewer program, and a distribution of the files both on .D81 disk images and plain files split 500 at a time into several subdirectories. The plain files are wonderful, these are data files, documents if you will, like JPEGs, only they are a small PETSCII BOT format. The perfect candidate for a datatype loader in C64 OS.
The only problem is that the files consist of a numbered name and the generic extension ".c64" (They are also SEQ-type files, which was a good decision. They are indeed simple sequential data files.)
As you can see, the filenames have a uselessly non-specific extension (".c64" does not tell you what type of data the files contain,) because the person who put this together is thinking like a classic C64 user. A world of isolation, with a copy of the viewer on each disk, and the rest of the disk filled up with as many data files as will fit. There is no room for anything else on the disk, so the data files and the viewer live in the same, isolated, storage-saturated, directory. To view the files you load and run the viewer first, and the viewer automatically loads the files from the current partition, and the current directory, of the current device, IF YOU'RE LUCKY! There is also a better than 50/50 chance that the viewer will hardcode reading from device 8. (See note about this below.)
In an operating system, such as C64 OS, but any OS really, where single Applications can open files of multiple datatypes and individual files can be opened by different Applications, it's critically important that data files receive a type identifier. That means a unique filename extension. The first thing I did was change all of the PETSCII BOT files from .c64 to the .pbot extension.
How easy is it to not hardcode device 8?
When a file is loaded from a device using the KERNAL (which is how a program is first loaded from the READY prompt, even if it later takes over with its own disk access routines), the device number that it reads from is saved to zero page, at $00BA (decimal 186.)
Try it. Load anything from a device number that's not 8, then peek 186.
load"$",10 print peek(186)
You'll see that if you loaded from device 10, address 186 ($BA) holds the number 10. In your program, when you want to load a data file using the KERNAL, you'll use a combination of SETNAM (to set the filename) and SETLFS (to set the logical file number, device number and secondary address.) Then you'll either use LOAD or OPEN followed by a series of CHRIN calls to read the data one byte at a time.
When you call SETLFS, you have to provide the device number. Very often programmers will simply hardcode #8 here. But to load from the same device that the program was loaded from, all you have to do is load the X register from $BA instead. It's an extraordinarily simple change.
Instead of doing this: lda #1 ;logical file number ldx #8 ;hardcoded device number ldy #2 ;secondary address jsr setlfs Just change it to this: lda #1 ;logical file number ldx $ba ;last used device number ldy #2 ;secondary address jsr setlfs
Although it's easy enough to blame laziness, the difference here is so small that it hardly seems plausible to be a matter of laziness. Rather, it seems to be just a bad habit, born from lack of knowledge, indifference, or the fact that many (perhaps most) books about programming the C64 from the 80s told you to just load from device 8. And why did they tell you that? Because they either didn't know or they had little mind for the future.
Please, for the love of more than one device on the bus, do not hardcode device #8.
Datatype loaders and the PBOT file format
Now that we know that data files, in the context of a more modern operating system, really need to have a datatype indicator and that a filename extension is the best way to do this, let's talk about datatype loaders in C64 OS.
Executable programs have no filename extension
A brief aside. Just like on Unix, and its derivatives like macOS, files that are executable programs do not have a file extension. This standard is carried on by C64 OS. Programs like the Configure Tool, the Setup Tool, the main booter, etc. are just a filename of type PRG with no extension. Any file of type PRG that is not an executable program, therefore, should have an extension, such as .koa or .kla for koala files.
The .PBOT format is super simple, but it's perfectly illustrative of a data file format that can be identified by a filename extension. The files come in 2 sizes: Small and Big.
Small The small size consists of 7 rows of 5 columns, for a total of 35 characters. The file is exactly 70 bytes, which is 35 bytes of C64 color codes (i.e., VIC-II color values, not PETSCII color codes) followed by 35 bytes of screen codes (i.e. not PETSCII characters.) They are laid out from left to right, top to bottom. And they assume the standard character set which came in the original C64 character ROM.
Big The big size consists of 16 rows of 12 columns, for a total of 192 characters. The file is exactly 384 bytes, which is 192 bytes of C64 color codes (i.e., VIC-II color values, not PETSCII color codes) followed by 192 bytes of screen codes (i.e. not PETSCII characters.) They are laid out from left to right, top to bottom. And they assume the standard character set which came in the original C64 character ROM.
With the file format specified, PETSCII BOTs are no longer limited to "Robots", and they are no longer limited only to the artistic endeavor of Cal Skuthrope. Anyone can make any small PETSCII art that fits this file format, and they will open and be viewable by anything that can display the format.
The C64 OS v1.04 update includes a tool in //os/c64tools/ called bigbotview. It takes a filename and loads in and shows the big version of the PETSCII BOTs, and it's just written in BASIC.
In C64 OS, the Image Viewer Application has the ability to view PETSCII BOTs, big or small version, by means of a datatype loader. Image Viewer can open many different types of files, so it needs to be able to identify the datatype of the file you ask it to open. The filename extension plays a double role. If you open a file from File Manager, the Opener Utility uses the extension to lookup an assigned Application. (An assign is included in v1.04 that assigns Image Viewer as the default opener for .pbot files.) When Image Viewer opens, it then has to do something with the file reference to a file with a .pbot extension. Alternatively, you could open Image Viewer first, then say File → Open... and from the Open Utility, pick a .pbot file and click open. Either way, Image Viewer then has a file reference to a file and it has to do something with it.
Since Image Viewer depends on datatype loaders, the first thing it does is extract the filename extension from the file reference. Because this is an "image" viewer specifically, it looks for an "image" datatype loader. It wouldn't be enough for an image viewing Application to find any old datatype loader for .pbot files. What would happen, for example, if .pbot files had a datatype loader but it was for audio data? Image Viewer has to find a datatype loader for .pbot files and also know that it's going to result in usable image data.
How it does this is very simple. It composes a datatype loader filename, "img.pbot.r" and then it tries to load that relocatable component (hence the .r extension) from the //os/library/loaders/ directory. If that loader doesn't exist, then it can't load that type of file. If the load does exist, then it gets loaded and relocated. All image datatype loaders have a common API.
What does the pbot loader actually do?
It knows how the data is structured in the file, but it has to provide the Application with some kind of standard usable data format.
A usable data format means that it specifies the video mode, and then provides data in the format that the VIC-II needs it, for that video mode.
The gfx.lib and KERNAL support for split- and fullscreen graphics modes support all the character modes, plus they support those character modes with a custom characterset (sometimes called a tileset.) The character modes require one screen matrix buffer, one color matrix buffer, a border color, and (depending on the exact mode) sometimes one or more background colors.
Therefore, the datatype loader allocates 4 pages for screen matrix. Where those actually come from in memory, no one knows, except that they're guaranteed to be a contiguous group of 4 pages. Then it allocates 4 pages for color matrix memory. Same deal, the 4 color pages will be together, but the color and screen buffers might not be contiguous with each other. Then it pre-fills the screen matrix buffer with $20 (space) and the color matrix buffer with $00 (black). Additionally, it allocates 2 pages for the raw data read buffer. That's enough to hold the 384 byte big version.
The file format doesn't have any additional information about the pbot size. (It's a very basic format.) It simply reads 70 bytes, and then checks to see if it has reached the end of the file. If it has, it flags it as a small version and closes the file. Otherwise it flags it as the big version and proceeds to read in the next 314 bytes (384 - 70 = 384.)
With the data in the read buffer, and a flag indicating small or big, it then copies the color data (in rows and columns) into the middle/center of the color buffer, and then copies the screen data (in rows and columns) into the middle/center of the screen buffer. It no longer needs the raw data read buffer, so it deallocates those 2 pages.
Lastly, pbot files use the standard characterset from a regular C64 character ROM. However, in C64 OS, the VIC-II is configured to see video bank 0 ($c000 to $ffff, the video banks are numbered in reverse, bank 3 is $0000 to $3fff.) The physical character ROM is not accessible by the VIC-II when it's configured for bank 0. (It's only available in banks 1 and 3.) So the datatype loader allocates a 2KB bitmap buffer and copies the real Char ROM into that buffer.
And that's it! The datatype loader provides an API for accessing the pointers to the data and the low-level graphics support of C64 OS does the rest.

Two big PETSCII Bots opened in Image Viewer
Sample PETSCII BOT image files
Here are a couple of sample PETSCII BOT files. Note that when they get transferred to the C64, they should be SEQ-type files. If they get transferred as PRG-type, they can still be viewed in C64 OS, but the default assign is for seq/pbot, and so you may need to choose Image Viewer manually from the Opener Utility and assign it as the opener for prg/pbot too.
- 0002big.pbot (SEQ, big version)
- 0004big.pbot (SEQ, big version)
- 0005bot.pbot (SEQ, small version)
- 0008bot.pbot (SEQ, small version)
New Screenshot v2 format
Let's move on to another file format used in C64 OS.
Since early betas, C64 OS has had the ability to take screenshots using a customizable global keyboard shortcut. The shortcut loads the grab.lib which saves the current character-mode screen to a file in //os/screengrabs/.
A screenshot is saved as a file with a ".pet" extension. I'm not 100% sure that this rather common extension is not already in wide use for another format of PETSCII file. However, I chose it because its data content is a PETSCII graphic image. Rather than just being the raw data, this format has some headers for metadata and a version number.
UPDATE: September 1, 2023
This section has been revised since this post was originally published. I discovered that there was a critial flaw in the v1 format; it doesn't specify whether the character set from the CHAR ROM should be the Uppercase/Graphics or the Lowercase/Uppercase set.
To accommodate this oversight, I've introduced a version 0. V0 and V1 are identical, except that v0 implies the Uppercase/Graphics charset, which seemingly 99.9% of all PETSCII graphics are produced in. V1 implies the Lowercase/Uppercase charset, which, although far less common, it's good to have available.
The Version 0 Format
MAGIC 3 ("PET", $D0 $C5 $D4)
VERSION 1 ("0", $30)
SOURCE 17 (Title, String in PETSCII, $00 padded and terminated)
AUTHOR 17 (Artist, String in PETSCII, $00 padded and terminated)
RELEASE 17 (Copyright, String in PETSCII, $00 padded and terminated)
SCREEN 1000 (Screencodes for screen matrix memory, not PETSCII codes.)
COLOR 1000 (VIC-II colorcodes for color memory, not PETSCII codes.)
BORDER 1 (Border color, value stored to VIC+$20)
BACKGRND 1 (Background color, value stored to VIC+$21)
The Version 1 Format
MAGIC 3 ("PET", $D0 $C5 $D4)
VERSION 1 ("1", $31)
SOURCE 17 (Title, String in PETSCII, $00 padded and terminated)
AUTHOR 17 (Artist, String in PETSCII, $00 padded and terminated)
RELEASE 17 (Copyright, String in PETSCII, $00 padded and terminated)
SCREEN 1000 (Screencodes for screen matrix memory, not PETSCII codes.)
COLOR 1000 (VIC-II colorcodes for color memory, not PETSCII codes.)
BORDER 1 (Border color, value stored to VIC+$20)
BACKGRND 1 (Background color, value stored to VIC+$21)
The Version 2 Format
MAGIC 3 ("PET", $D0 $C5 $D4)
VERSION 1 ("2", $32)
SOURCE 17 (Title, String in PETSCII, $00 padded and terminated)
AUTHOR 17 (Artist, String in PETSCII, $00 padded and terminated)
RELEASE 17 (Copyright, String in PETSCII, $00 padded and terminated)
SCREEN 1000 (Screencodes for screen matrix memory, not PETSCII codes.)
COLOR 1000 (VIC-II colorcodes for color memory, not PETSCII codes.)
BORDER 1 (Border color, value stored to VIC+$20)
BACKGRND 1 (Background color, value stored to VIC+$21)
CHARSET 2048 (2KB character set)
The verion 02 and version 1 formats are identical, except that the version 0 format implicitly uses the Uppercase/Graphics character set, from the standard C64 character ROM, and the version 1 format implicitly uses the Lowercase/Uppercase character set.
The problem with using the the v0 or v1 format for screenshots is that it doesn't preserve the character set. And since C64 OS uses a custom character set, the resultant screenshot is not truly complete. Even if you tried to use the default C64 OS character set, it still wouldn't be complete because at any given moment when a screengrab is taken there could be custom characters loaded in, as their often are by Utilities that show cool little icons.
The version 2 format adds the character set to the end of the file. It adds 2KB to the file though, so I think version 0 and 1 are still an appropriate format for PETSCII graphics where the C64's build in CHAR ROM is implied.
C64 OS v1.04 gains an image datatype loader for this .PET format. The datatype loader is thus found at: //os/library/loaders/:img.pet.r
We should be able to imagine what it does. It's almost the same as the PETSCII BOT loader. It loads the first 55 bytes from the file into a statically allocated structure. Then it allocates 4 pages for screen matrix memory and loads the next 1000 bytes into that. Then it allocates 4 pages for color memory and loads the next 1000 bytes into that. It reads the next 2 bytes into statically allocated memory, for the border and background colors.
The image datatype loaders have an API for returning the metadata and the video mode information extracted from a file. Image Viewer is able to display the source, author and release strings in its UI. PETSCII BOTs (and most other C64 image file formats) don't have this information, so the datatype loaders just provide blank strings when asked.
Finally, the loader allocates 8 pages for the character set. It checks the version number which was statically loaded in during the initial 55 byte header load. If it's version 0, then it copies the Uppercase/Graphics half of the CHAR ROM into the charset buffer. If it's version 1, it copies the Lowercase/Uppercase half of the CHAR ROM in the charset buffer. And finally, if it's version 2, then it reads the next 2048 bytes from the file into the charset buffer. Closes the file and it's done.
Sample files in each format
Here are a couple of sample files. The version 0 file was created by exporting the data from a PETSCII image that was released on CSDB as an executable PRG. Because the .PET version doesn't need to carry the viewer program around with it, it's smaller than the PRG version, despite also containing the source, author and release metadata!
The v1 files are screenshots taken from an early version of C64 OS. The v1 format is no longer used by C64 OS for screenshots, but, I couldn't find any PETSCII images on CSDB that use the Lowercase/Uppercase character set. Nonetheless, this format exists for completeness sake.
The v2 files are current C64 OS screenshots. Because they contain the custom character set, these reproduce the screen exactly as it appeared when the screenshot was taken.
Like PETSCII BOTS, these should be SEQ-type files when transferred to the C64. If they end up as PRG-type files, you may have to manually assign Image Viewer as the opener for them.
- thirtytwo.prg (PRG, Original PRG-release PETSCII image)
- thirtytwo.pet (SEQ, v0, export from PRG-release)
- colors.pet (SEQ, v1, deprecated screenshot, wrong character set)
- dndroller.pet (SEQ, v1, deprecated screenshot, wrong character set)
- screenshot.pet (SEQ, v2)
- filemansett.pet (SEQ, v2)
Commodore Grafix Format (CGFX)
Commodore Grafix is a much more ambitious file format. Its goal is to be a universal container format for C64 graphics, including all native video modes and at least the most common non-native video modes. Plus support for metadata, variable frame size, multiple frames, and extra information about how the multiple frames are related to each other. That means either matrix images or animations, each with various properties.
What is the point of this format?
The fundamental point is to decouple graphics data from graphics presentation.
On the Commodore 64, it is very common for graphics data to be rolled up inside a single PRG file that is loadable and runnable. This seems to kill several birds with one crappy solution. Let's list the dead birds:
- The user doesn't have to worry about what format the image is.
- The user doesn't have to have a viewer program.
- The artist gets to combine non-standard effects in novel ways.
- The files of different formats are distributed and consumed the same.
So why is this a crappy solution? Because there is also one and only one way to view the data embedded in these programs. They must be loaded from the READY prompt. They take over and put data into memory wherever they want. Sometimes the artist doesn't care that the viewer only works on PAL, and doesn't even bother to tell the user that this is unsupported by NTSC.
How easy is it to detect NTSC?
As easy as it is to not hardcode device #8, it's almost as easy to detect that your PAL-only software is running on an NTSC machine and gracefully bail out.
Both PAL and NTSC machines use the same KERNAL ROM. But there are reasons for knowing whether this is a PAL or NTSC machine. Mainly, for RS-232 timing over the user port. On power up and on reset, the KERNAL performs a simple test of the VIC-II to see if it reaches a raster line that is only available on PAL machines. Then, to the address $02a6, it writes a 1 if the machine is PAL, or a 0 if the machine is NTSC.
This test may not be sufficiently precise for the needs of some games or demos, but if you know your code definitely won't run on an NTSC machine, and $02a6 is 0, then you know enough to exit gracefully. And this is all it takes to do that:
lda $02a6
bne pal
rts
pal
If you want to be just the smallest amount more friendly, you could output the message: "pal only." with a similarly miniscule amount of code.
lda $02a6
bne pal
lda #<msg
ldy #>msg
jmp $ab1e
msg .null "pal only."
pal
Considering that this can be done with just 22-bytes, why don't people do this? Again, they either don't know, or more likely, they just don't care.
We're not asking you to support NTSC. We're asking you to just have the courtesy to tell us that we're not supported, rather than letting our computer lock up in an explosion of colors.
Separating graphics data from presentation allows for some standard analysis of what the data are, and then for a routine to be brought to bear on the data to render it. On the naked C64 this is too much work. But in an operating system, like C64 OS, having graphics data rolled up inside a custom viewer program means there is no way to even try to render these graphics.
Comparison to other graphics formats
Most of the other graphics file formats are just like Koala, but they are variations on that theme. They have different load addresses, that put native-mode graphics data into the right places in memory, leaving some to be bumped or shifted a little bit, so that the VIC-II can then be configured to point at the right bank, and the right offsets within that bank, to display the data.
These formats usually have no metadata, they have no indication at all of what kind of data they contain (which is why using a meaningful filename extension is so important,) and they often contain useless padding bytes to do stuff like move screen matrix data out past the end of a bitmap. (8000 bytes of bitmap, followed by 192 bytes of padding, followed by 1000 bytes of screen matrix, aligns the screen matrix with somewhere the VIC-II can use it.)
Commodore Grafix is a RIFF/CGFX container. RIFF is a great format. Its predecessor, IFF, which stands for Interchange File Format, was first introduced by Electronic Arts on the Amiga in 1985. It stores 32-bit integers big endian, because the 68K processors used in the Amiga (and early Macintoshs) are big endian. RIFF (Resource Interchange File Format) was introduced by Microsoft a few years later. It's mostly the same as IFF, but the integers are little endian because x86 processors are little endian. The 6502 is only an 8-bit processor so it's not that important what endianness the file format uses. But I prefer it because the 6502's 16-bit pointers are little endian, so it feels more at home.
The great thing about RIFF (or IFF) is that it is extensible, while remaining backwards compatible. The format stores multiple, nested, identifiable chunks. A loader that reads the file format in can be proactive and anticipate that unrecognized chunks may be found in the file, and it can ignore those by skipping over them. Each chunk's size is specified, so the unsupported ones are easy to skip.
There is usually some required order to the chunks, for example a small chunk that describes the data's format is usually required to come before the much larger data chunk. This allows a program to easily read in the format information, and then bail out early if the format is unsupported. If it is supported, then it can proceed to find the data chunk. There is usually some flexibility about the order of other optional chunks.
One reason why modern computers have outgrown RIFF is because its 32-bit integers limit the size of a chunk to 4 gigabytes. Call me crazy, but I don't think this is going to pose a problem on the Commodore 64.
A recap on how RIFF is formatted
RIFF only defines the chunk structure of the container. It doesn't in any way define the meaning of the data within a chunk. In order to know how a chunk's data is structured, you have to refer to the documentation. Each chunk is identified by a 4 byte ID, followed by a 4 byte size, where the size is the size of the chunk's data. This is done very specifically so that first you read in the 8 byte chunk header, which moves the file pointer to the start of the data. Then, if you don't recognize the chunk ID, you can skip the chunk by moving the file pointer ahead by precisely the number of bytes specified in the size, and now the file pointer is positioned at the start of the next chunk header (also conveniently skipping any nested subchunks.)
There is a clever piece of recursion here though. RIFF files all begin with a chunk, whose chunk ID is "RIFF" (all caps in ASCII, i.e., $52 $49 $46 $46, or "riff" in PETSCII.) But, how is a RIFF chunk's data formatted? Gotta read the documentation for that, and it says that the first 4 bytes of its data segment are a media ID, followed by additional chunks. Many people are confused about this, and think that somehow RIFF is complicated, because the first header is 12 bytes long, RIFF, followed by a size that is the data size minus 4, followed by the media ID. No no, don't over think it. The entire file is in fact one properly structured chunk. It has an 8-byte chunk header. The size in the header is the size of the data segment. But to understand how the data is structured, you need to understand how a chunk with an ID of RIFF is structured, and it says that the first 4 bytes of the "DATA" segment are a media ID.
For more details and some pretty pictures about how RIFF files are formatted, see the blog post, GeoRAM, DigiMAX and NMI Programming → The RIFF Wave File Format.
Commodore Grafix RIFF format
Being a RIFF container, the first 4 bytes are RIFF (i.e., $52 $49 $46 $46, or "riff" in PETSCII.) The next 4 bytes are the size of the data segment, which is not particularly important. The media ID is "CGFX" (i.e., $43 $47 $46 $58, or "cgfx" in PETSCII.) This tells us that the file will definitely have a "FRMT" chunk and a "DATA" chunk, with the FRMT chunk coming first. It may also have a "META" chunk, which may come before or after the FRMT chunk but before the DATA chunk. There may be a "SPRT" chunk for sprite data, which may come before or after the DATA chunk, but I haven't defined the SPRT chunk yet.
The metadata chunkThe META chunk, if present, has a size of $80 (i.e. $80 $00 $00 $00, in the file because it's little endian).
This consists of 4 fields that are $20 (decimal 32) characters long: Artist, Source, Year/release, Title. Each field must be NULL terminated, and will usually be NULL padded out to fill the 32 bytes, but the padding byte doesn't really matter, since the string's NULL terminator indicates where the string ends.
The format chunkThe FRMT chunk, which must be present, has a size of $0c ($0c $00 $00 $00, little endian.) This can be visualized as 3 rows of 4 bytes each.
Loosely categorized as, matrix info (4 bytes), animation info (4 bytes), data info (4 bytes.)
— Matrix infoMatrix rows, matrix columns, start row index, and start column index. Matrix rows and columns are a count of the number of rows and columns of frames there are. These are unsigned 8-bit integers, from 1 to 128. With a limitation that their product must be <= 256. E.g., a matrix can consist of 3 rows and 85 columns (3 x 85 = 255), or 16 rows and 16 columns (16 x 16 = 256), but 20 rows and 20 columns is invalid, because the total number of cells would exceed 256 (20 x 20 = 400.)
The start row and start column are 0-based indexes, which must range from 0 to the number of rows or columns minus 1. E.g., if matrix rows = 5, then a valid start row index may range from 0 to 4. If matrix columns = 45, then a valid start column index may range from 0 to 44.
— Animation infoFrame count, frame delay, loop count, and media control. Frame count is an unsigned integer from 1 to 255 which must be equal to matrix rows times matrix columns. Frame delay is an unsigned integer which is the time delay between each frame measured in 1/10ths of a second. A frame delay of 0 means the frames are not animated. The maximum framerate is 10 FPS by setting the frame delay to 1. Loop count is an unsigned integer that counts down how many times the animation should be played before it stops. A loop count of 0 means that it repeats indefinitely. Media control is a byte that describes how the media behaves or can be interacted with.
The following table lists the available media control values at the time of this writing.
| Value | Constant | Description |
|---|---|---|
| 0 | mcl_stat | Static Image |
| 1 | mcl_loop | Looping Animation |
| 2 | mcl_bnce | Bouncing Animation |
| 3 | mcl_hwrp | Horizontally Wrapping Matrix |
| 4 | mcl_vwrp | Vertically Wrapping Matrix |
| 5 | mcl_mtrx | Non-Wrapping Matrix |
For an image with only a single frame, the media control will indicate a static image (mcl_stat.) If the frames are an animation, the media control must be either looping or bouncing styles of animation. Loop means the animation plays from the first frame to the last frame, then immediately continues to the first frame and repeats by counting up to the last frame again, until the loop count expires. A bouncing animation plays from the first frame counting up to the last frame, and then reverses direction and counts back down to the first frame. Each loop count represents one complete bounce.
Media control for matrix imagesFor a matrix image—an image with more than one frame in either rows, columns or both—you can define in which direction the matrix wraps. For example, in the teapot 3D model, there are 5 rows and 8 columns. The 8 columns are taken from 8 angles in 360° around the object. The 5 rows tilt the object so that you're looking down at it from the top, looking at it from the center line, or lookup up at it from the bottom. In this case, this matrix wraps horizontally.
An example of a 3D model that might reasonably wrap vertically is an image of a car tire. Where dragging up and down continuously rotates the tire, and dragging left and right changes your perspective of whether you're looking at one side of the tire, front on to the tread of the tire, or looking at the other side of the tire.
Scenes into which you are looking, are generally horizontally wrapping. Dragging up would cause you to look towards the ground, dragging down would cause you to look towards the sky. Dragging left pans you rightward through the scene and vice versa. The perspective of a 3D model and a scene are inverted; this is handled by inverting the order of the frames in the matrix. A scene may be horizontally wrapping, or if there is not 360° of data, it could instead be just a non-wrapping matrix. A non-wrapping matrix can also be used for a 3D model, if the model cannot be freely rotated in 360°.
The standard conception of a panoramic image is a matrix with 1 row and several columns, which is non-wrapping but allows the user to pan left and right to see the whole thing.
— Data infoFrame size rows, frame size columns, video mode, video attributes. These properties are used to define the frame data. Each frame must have the same data structure. E.g., it is not possible for one frame to be a MultiColor bitmap and another frame to be in HiRes character mode.
Due to constraints of the video modes of Commodore 8-bit computers, frame sizes cannot be specified in pixel precision. Instead, the frame size is specified in 8x8 character rows and columns. A standard full screen frame on a C64 is 25 rows and 40 columns. These properties are unsigned integers with a range from 1 to 255. If converted to pixels this gives the frame size of a Commodore Grafix image a range from 8x8 pixels up to 2040x2040 pixels.
Video mode is a defined integer, permitting the format to support up to 256 possible video modes. The currently defined video modes are:
| Value | Constant | Description |
|---|---|---|
| 0 | vdm_stchr | HiRes Character |
| 1 | vdm_mcchr | MultiColor Character |
| 2 | vdm_ebchr | Extended Background Character |
| 3 | vdm_hrbmp | HiRes Bitmap |
| 4 | vdm_mcbmp | MultiColor Bitmap |
Video modes specify native modes that the various video chips can be put in. The first 5 are the native video modes of the VIC-II, but additional modes could be defined for other native modes of the video chips found in other Commodore 8-bit computers, such as the VIC in the VIC-20, the VDC in the C128 or the TED in the Plus/4.
Video attributes define standard modifications to native video modes. The video attributes byte is a bit field, allowing for some bit combinations if they make sense. The first 5 bits are defined so far:
| Value | Constant | Description |
|---|---|---|
| %0000 0001 | vat_fli8 | 8 color fields per cell |
| %0000 0010 | vat_fli4 | 4 color fields per cell |
| %0000 0100 | vat_lace | Odd and even frames are interlaced |
| %0000 1000 | vat_xshf | Even interlaced frames are shifted 1px to the right |
| %0001 0000 | vat_bgnd | Custom background color for every row |
Since the video attributes represent modifications of native video modes, let's talk about what these represent. The C64 community has developed a series of obscure names (and accompanying acronyms that are even more obscure), most of which define native modes with one or more video attribute. For example, MCI stands for MultiColor Interlaced. It is two frames of standard MultiColor bitmaps which are interlaced, with one frame shifted by one pixel on the X axis. In CGFX, this is simply a file containing two frames of data, the video mode is vdm_mcbmp, and the video attributes are vat_lace|vat_xshf (OR'd together.)
Another non-standard mode is FLI, which stands for Flexible Line Interpretation (for some reason), is a MultiColor bitmap but instead of a single colormap (1000 bytes of color), it has 8 colormaps (each one is 1000 bytes), and the colormaps are rotated through on each rasterline, increasing the color density of each 8x8 cell. In CGFX, the video mode is vdm_mcbmp, and the video attribute vat_fli8 is used, to indicate 8 colormaps.
What was, for a long time, the most advanced non-standard video mode is called IFLI, which stands for Interlaced Flexible Line Interpretation. This is, conceptually, a combination of MCI and FLI. Like MCI, the video mode is MultiColor bitmap and there are two frames interlaced with an X-shift on one frame. But then there is the addition of the 8 colormaps and their rotation on each rasterline. This is easily described in CGFX as, video mode is vdm_mcbmp, and video attributes are: vat_fli8|vat_lace|vat_xshf.
Those acronyms are fairly easy to remember and make a certain amount of sense. But as mode and attribute combinations multiply, the names and acronyms used to describe them become increasingly obscure and inscrutable. They are, however, easily captured by CGFX. For example, there is a variation of all interlaced modes in which the second frame is not X-shifted. It gives the artist an increase in color options, but doesn't give any increase in resolution, but with the advantage of less flickering (especially if the overlapping colors are chosen carefully.) What would one call all these extra modes? I have no idea, but in CGFX, one simply unsets the vat_xshf bit, and boom now you have MCI or IFLI sans the 1 pixel shift.
There are, of course, HiRes interlaced, HiRes FLI, and HiRes interlaced FLI. Plus there are x-shifted and non-x-shifted versions of the interlaced. What are the acronyms for those modes? Not the slightest clue. But, again, these are all just simple combinations of video mode and video attributes.
There are some combinations that are meaningless, naturally. For example, character modes do not use colormaps in main memory. The FLI modes are only possible because in addition to one colormap in the static color RAM—there is not enough time to move this around—they also have a colormap in main memory that is pointed to with registers. There is enough time to change those pointers so that every raster line points at a different colormap. Character modes don't have those colormaps so combining them with the FLI8 attribute makes no sense. That said, even the VIC-II has mode bits which cannot be used in every possible combination.
The other two attributes, I'll just briefly say what they are. FLI4 is an alternative to FLI8 in which there are 4 colormaps, and you only need to change the colormap every second raster line. It's a lower color density for a smaller file size. A standard FLI8 display routine can be used, simply by duplicating the colormaps in memory when loading them from the file.
Background (vat_bgnd) is an interesting alternative way to increase color density. It's sometimes called background 200, because it consists of a list of 200 background colors. On each raster line you read the background color for that line from the list and set the VIC-II's background color from it. This background color is shared horizontally across an entire raster line, but it can be different on every rasterline instead of shared by the whole screen. I chose not to call it "Background 200," because Commodore Grafix files can have variable frame sizes. Therefore, if this attribute is set, the expectation is that the frame data will include a set of background colors equal to the row height of the image times 8. If the image is just 10 rows high, it would include a list of 80 background colors. If it's 50 rows high, it would include a set of 400 background colors, and so on.
Other custom video modes often include sprite overlays. These are going to be handled by CGFX via a SPRT chunk. This chunk's format has not yet been defined, but will be added to the specification in the future.
For an example list of the most classic native and custom C64 graphics formats, see the page C64 graphics modes, by DMAgic. It's from 1999, so the newer formats are not mentioned.

Screenshot of the c64 graphic modes webpage.
The data chunk
Somewhere following the format chunk, and the metadata chunk if it exists, comes the data chunk.
The DATA chunk, has a size that is variable, depending on all the information in the format chunk.
The data consists of frames. Each frame consists of a set of frame components, which always come in the same predictable order. However, which components and the size of the components depends on the value of properties in the format chunk. Once the size of a single frame is determined, if there are multiple frames, each frame will have exactly the same size and structure as every other. The frames are packed together end-to-end with no padding.
The size of the DATA chunk is, therefore, exactly equal to the size of one frame times the number of frames. Discussion of the frame components, order and structure is broken down in the next section.
Frame Structure and Components
A frame is made up of all required frame components for the specified video mode and video attributes.
There is an order to the frame components, and all required frame components are included and come in the correct order. If a frame component is not required, it is not included.
There are no gaps or padding, either between frame components or being frames.
Interlaced modes combine odd and even frames into pairs. Therefore, any Commodore Grafix file with the interlaced video attribute set, must have an even number of frames.
The Ordered Frame ComponentsThe frame components, in order, are:
- bitmap
- charset
- charmap(s)
- colormap
- border color
- background color(s)
If a video mode or attributes don't need a component, the component isn't there. But the ones that are there always come in this order. Let's discuss the details on these:
bitmapA bitmap is in the VIC-II's bitmap byte order. 8 bytes per 8x8 pixel cell. However the number of cells in the frame depends on the format chunk's data info, frame size rows and frame size columns. Usually this is 25 x 40, which is 1000 cells, which means the bitmap component will be 8000 bytes. However, the frame size can vary, so the bitmap size must be computed as frame size rows x frame size columns x 8.
charsetA charset is in the VIC-II's character set byte order. 8 bytes per character. How big the charset is depends on the video mode. A charset is not used at all in the bitmap modes. In the standard and MultiColor character modes, a charset must have 256 characters and thus is 256 x 8 = 2048 bytes (2KB) exactly. If the video mode is Extended Background (vdm_ebchr) then there are only 64 characters, and the charset is 64 x 8 = 512 bytes.
charmap(s)A charmap consists of 1 byte per frame cell. So, just like the bitmap size calculation, you use the frame size rows x the frame size columns to compute the number of cells, and that is how many bytes the charmap is.
A charmap is used as a set of indexes into the character set in character modes. And is used as a color map in bitmap modes. This is just how the various video modes use a charmap, it is not relevant to the file format or structure of a frame.
If the video attribute FLI4 (vat_fli4) is used, then the frame has 4 charmaps, each identically sized, in a row. If the video attribute FLI8 (vat_fli8) is used, then the frame has 8 charmaps, each identically sized, in a row.
colormapA colormap consists of 1 byte per frame cell. Just as with bitmap and charmap size calculation, use the frame size rows x the frame size columns to compute the number of cells, and that is how many bytes the colormap is. However, only the lower nybble of each byte is relevant. The upper nybble, when copied to the static color RAM, is lost.
In all character modes, one colormap is included in the frame. In MultiColor bitmap mode, one colormap is include in the frame.
border colorAlways one byte. Included here in all frame formats, because the border has a color in all video modes. Note, that, because the border color is present in every frame, in a matrix image or even in an animation, it is possible for the border color to be unique per frame.
background color(s)How many background color bytes there are in a frame depends on the video mode, plus the video attribute vat_bgnd. First, assuming that vat_bgnd is not used, the number of background colors can be seen in the following table:
| Video Mode | Background Colors |
|---|---|
| vdm_stchr | 1 |
| vdm_mcchr | 3 |
| vdm_ebchr | 4 |
| vdm_hrbmp | 0 |
| vdm_mcbmp | 1 |
Each of the background colors lines up with the VIC-II's background color registers. There are 4 background color registers, numbered #0 through #3, corresponding with VIC-II registers $21 through $24. In the frame, the background colors are filled in order. If there is just one background color, it goes in $21 (BGCol #0.), If there are 3 background colors, they go into registers $21, $22 and $23 respectively.
With the video attribute vat_bgnd set, the number of background colors is increased by the number of frame cell rows times 8, minus one. These additional background colors follow immediately after the background color specified for the VIC-II register $21, because they are the colors for that register (BGCol #0), but there is one for every pixel row, rather than just one global value. The following table summarizes the number of background color bytes, in each mode, assuming the frame size is the typical 25 rows.
| Video Mode | Background Colors |
|---|---|
| vdm_stchr | 200 |
| vdm_mcchr | 202 |
| vdm_ebchr | 203 |
| vdm_hrbmp | 0 |
| vdm_mcbmp | 200 |
Concordance of frame formats
Besides the new CGFX graphics format, C64 OS generally prefers the ArtStudio format for HiRes bitmaps and the Koala format for MultiColor bitmaps. The reason is because they pack their frame data in the same component order, with no extra padding. These formats are ideal for an operating system, which loads the components into different regions of allocated memory anyway. Formats which include padding to position the bytes with a single primitive KERNAL load, that padding is just a waste of disk space and load time.
It is not a coincidence that a single frame of CGFX in the video mode and attributes that corresponds with ArtStudio has a frame that is structured identically to ArtStudio (sans the 2-byte load address.) And, a CGFX frame in the video mode and attributes that corresponds with Koala, you guessed it, has a frame structure identical to a Koala file (again, not including the 2-byte load address.)
There is just one exception for Koala. The Koala format doesn't define the border color. Given that Koala's video mode is MultiColor bitmap (i.e., vdm_mcbmp) it has one background color and that is its last byte. This is one byte out of order with the CGFX frame components. However, if you use the Koala's background color as the border color (a sensible decision), then that byte just gets duplicated anyway, and so the border then background colors in the CGFX frame format end up the same, so it's not a big deal.
Let me give an example of how this works:
If we were converting a Koala file into the frame data of a CGFX file, first comes the the CGFX header (all the RIFF stuff), followed by a RIFF chunk header for the the data chunk, which would have a size that's equal to exactly the size of one frame. That's 40 x 25 x 8 = 8000 bytes of bitmap data, plus 40 x 25 x 1 = 1000 bytes of charmap (used for color data in this video mode), plus 40 x 25 x 1 = 1000 bytes of color map, plus 1 border color, plus 1 background color, equals: 8000 + 1000 + 1000 + 1 + 1 = 10002 bytes. So the RIFF data chunk's size will be 10002.
The Koala file itself is exactly 10003 bytes. The first 2 bytes are the load header, $00 $60 (to load to $6000). Followed by 8000 bytes of bitmap, 1000 bytes of charmap, 1000 bytes of color map, and 1 background color. End of file; there is no border color. To use the Koala file for the frame data, we skip the first 2 bytes (the load address), and then the rest of the file gets tacked on as the frame chunk's data. The final byte, though, the background color falls at the position in the frame data of the border color, so we simply write that same final byte out a second time. And done.
Converting other file formats to frame data requires more work.
Standard Frame Formats
It can be difficult to go from a prose description of the frame format, to a clear picture of the frame format considering different video modes and attributes. The following is not a complete set of possible frame formats (as that would defeat the purpose of the format being combinatorially exponential), but a sample of frame formats for several common combinations of video mode and attributes and frame size. These examples, together with the explanation in the section above should make it clear how this works.
Standard Char (0)
| Component | Size |
|---|---|
| charset | 2048 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 1 |
| Total | 4050 (16 pages) |
MultiColor Char (1)
| Component | Size |
|---|---|
| charset | 2048 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 1 |
| bgcol #1 | 1 |
| bgcol #2 | 1 |
| Total | 4052 (16 pages) |
ExtBgnd Char (2)
| Component | Size |
|---|---|
| charset | 512 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 1 |
| bgcol #1 | 1 |
| bgcol #2 | 1 |
| bgcol #3 | 1 |
| Total | 2517 (10 pages) |
HiRes Bitmap (3) *
| Component | Size |
|---|---|
| bitmap (25x40) | 8000 |
| charmap (25x40) | 1000 |
| brdrcol | 1 |
| Total | 9001 (36 pages) |
* ArtStudio Format
MultiColor Bitmap (4) *
| Component | Size |
|---|---|
| bitmap (25x40) | 8000 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 1 |
| Total | 10002 (40 pages) |
* Koala Format, if you duplicate the brdrcol to bgcol #0
HiRes Bitmap (3) + FLI8
| Component | Size |
|---|---|
| bitmap (25x40) | 8000 |
| charmap 0 (25x40) | 1000 |
| charmap 1 (25x40) | 1000 |
| charmap 2 (25x40) | 1000 |
| charmap 3 (25x40) | 1000 |
| charmap 4 (25x40) | 1000 |
| charmap 5 (25x40) | 1000 |
| charmap 6 (25x40) | 1000 |
| charmap 7 (25x40) | 1000 |
| brdrcol | 1 |
| Total | 16001 (63 pages) |
MultiColor Bitmap (4) + FLI8
| Component | Size |
|---|---|
| bitmap (25x40) | 8000 |
| charmap 0 (25x40) | 1000 |
| charmap 1 (25x40) | 1000 |
| charmap 2 (25x40) | 1000 |
| charmap 3 (25x40) | 1000 |
| charmap 4 (25x40) | 1000 |
| charmap 5 (25x40) | 1000 |
| charmap 6 (25x40) | 1000 |
| charmap 7 (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 1 |
| Total | 17002 (67 pages) |
HiRes Bitmap (3) + FLI4
| Component | Size |
|---|---|
| bitmap (25x40) | 8000 |
| charmap 0 (25x40) | 1000 |
| charmap 1 (25x40) | 1000 |
| charmap 2 (25x40) | 1000 |
| charmap 3 (25x40) | 1000 |
| brdrcol | 1 |
| Total | 12001 (47 pages) |
MultiColor Bitmap (4) + FLI4
| Component | Size |
|---|---|
| bitmap (25x40) | 8000 |
| charmap 0 (25x40) | 1000 |
| charmap 1 (25x40) | 1000 |
| charmap 2 (25x40) | 1000 |
| charmap 3 (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 1 |
| Total | 13002 (51 pages) |
Standard Char (0) + vat_bgnd
| Component | Size |
|---|---|
| charset | 2048 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 200 |
| Total | 4249 (17 pages) |
MultiColor Char (1) + vat_bgnd
| Component | Size |
|---|---|
| charset | 2048 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 200 |
| bgcol #1 | 1 |
| bgcol #2 | 1 |
| Total | 4251 (17 pages) |
ExtBgnd Char (2) + vat_bgnd
| Component | Size |
|---|---|
| charset | 512 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 200 |
| bgcol #1 | 1 |
| bgcol #2 | 1 |
| bgcol #3 | 1 |
| Total | 2716 (11 pages) |
MultiColor Bitmap (4) + vat_bgnd
| Component | Size |
|---|---|
| bitmap (25x40) | 8000 |
| charmap (25x40) | 1000 |
| colmap (25x40) | 1000 |
| brdrcol | 1 |
| bgcol #0 | 200 |
| Total | 10201 (40 pages) |
Creating a CGFX file
C64 OS v1.04 includes a tool in //os/c64tools/ called CGFX Creator. When you load and run this tool, it works much like the tools for PRGAlias Creator, the Configure Tool or Setup Tool. It asks you a series of questions about the format of the file. One question for each configurable setting in the RIFF headers, with some intelligent defaults or skipped sections depending on what you chose in the previous questions.
The tool assembles all of the RIFF headers up to the data segment of the format chunk, and saves these as a file with the extension .cgh (for Commodore Grafix Headers.) You have to then prepare the frame data. Just as an example, let's say you're creating a 3 frame panorama, from 3 images that have been converted on a PC to Koala format (perhaps using the image conversion service at services.c64os.com.)
Suppose that you have the three Koala files, and you happen to know that the background color on each is black (this is very common.) To prepare these as frame data, you can use the filecrop tool. Let's say our koala files are called frame1.koa, frame2.koa and frame3.koa. Load and run //os/c64tools/:filecrop. When it asks for the input filename, enter frame1.koa. When it asks for the start offset (how many initial bytes to skip), we'll say 2, to skip the load address. When it asks for how many bytes of length, we'll say 10001. The output filename we can say is frame1.frm (or frame1.dat or whatever,) to indicate it's a frame of raw data.
The only problem now is that those raw frames are missing their background #0 color byte. The background color byte in the original file data is at the position of the border color. We can use some BASIC commands to append the byte 0 (black) to the end of each frame.
open2,8,2,"frame1.frm,p,a" print#2,chr$(0); close2
This opens the file for append. The ",a" is for append. The ",p" is for PRG, if the raw frame file happens to be SEQ, we would use ",s" instead of ",p". The print#2,chr$(0); writes out a single binary byte of $00 (the color black.) Mind the semi-colon! It's absolutely necessary. Without it, the print# command will also output a carriage return. But that would make the frame file format invalid and also totally broken, as it would offset all subsequent frames by one byte.
If you're processing several frames, it is possible to use a simple BASIC program to script the addition of the final byte. Like this:
10 dv = peek(186):rem current dev# 20 for i=1to5 30 read f$ 40 open2,dv,2,f$+".frm,p,a" 50 print#2,chr$(0); 60 close2 70 next 80 end 90 data frame1,frame2,frame3,frame4,frame5
Finally, with the CGFX headers prepared, and all of the frame data prepared, we can use the DOS concatenate command to join the files together. (Assuming we named the file "image" using CGFX Creator tool, otherwise, use whatever filename you want to name the image.)
open15,8,15 print#15,"c:image.cgx=image.cgh,frame1.frm,frame2.frm,frame3.frm" close15
There you go. You now have a file called image.cgx, which has all the RIFF headers for the panorama image, followed by the 3 frames of data in MultiColor bitmap mode, all packed neatly into a single file, with metadata, etc. Ready to be opened and viewed in Image Viewer, or distributed to other C64 users.
Eventually there will be tools that can create these files in a more automated way. But this is an example, using simple tools already available, plus built-in BASIC and DOS commands to assemble the components together to create a CGFX file. Also being so manual helps us see, at a low-level, just how the sausage gets made.
About a week after publishing this blog post, I decided that it would be fun to shoot a video that walks through the complete process of selecting a cool animated GIF, downloading it, splitting it into frames, converting the frames to Koala, packing those into a set of frames for a CGFX animation, copying them to the C64, and using the CGFX Creator Tool to make the headers. Finally, using the CBM DOS concatenate on copy command to assemble the headers and the frame data into a final file, then loading it up and playing it. Here is the video result of that fun little thought.
Sample CGFX Files
Here are some sample CGFX files. All of these files are multi-frame files, a couple of panoramas, three animations and a 3D object. In order to view any of these files in Image Viewer for C64 OS, a 17xx REU is required. You should generally be able to see why this is the case by looking at the file sizes, which range from 30KB (remember, the OS and Application are in memory at the same time,) to 360KB.
The CGFX file format, inherently, does not require an REU. The format can be used to contain many different formats of single-frame, still images, none of which require an REU. Additionally, a viewer could be written to extract or view any individual frame from a multi-frame image, and that wouldn't need an REU either.
- austria.cgx (SEQ, 30KB, Panorama)
- beach.cgx (SEQ, 60KB, Panorama)
- boneskirk.cgx (SEQ, 190KB, Animation)
- earth.cgx (SEQ, 360KB, Animation)
- porche.cgx (SEQ, 240KB, 3D Object)
- warp.cgx (SEQ, 280KB, Animation)
Final Thoughts
I hope this piques some curiosity! I hope someone will use this information to make some Python scripts or a webservice, that can do some cool things, like take a panoramic photo, chop it up into pieces, convert the frames to some C64 image format, and then convert and pack the frames with the correct CGFX headers, to generate a matrix panorama image. Even better would be an automated way to convert animated GIFs to CGFX animations, or 3D objects to CGFX 3D matrix images.
The sample images that I've created, which can be downloaded here (cgfxsamples1.car), were created using the manual process described above.
Many combinations await that I have not even begun to experiment with. Such as Extended Background character mode animations with a custom character set. This would be so cool to see. Image Viewer should already have support for that format, even though no one (including me) has ever put one together. The future holds many fun experiments and lots of cool options.
- Besides just the limitation of only 256 possible file types. That limit, in practice, was never even close to being reached. There just weren't enough major applications written for the platform.
- The .PET datatype loader in C64 OS v1.04 supports the v1 and v2 formats only. An updated datatype loader with support for the v0 format will be released in C64 OS v1.05.
Do you like what you see?
You've just read one of my high-quality, long-form, weblog posts, for free! First, thank you for your interest, it makes producing this content feel worthwhile. I love to hear your input and feedback in the forums below. And I do my best to answer every question.
I'm creating C64 OS and documenting my progress along the way, to give something to you and contribute to the Commodore community. Please consider purchasing one of the items I am currently offering or making a small donation, to help me continue to bring you updates, in-depth technical discussions and programming reference. Your generous support is greatly appreciated.
Greg Naçu — C64OS.com


