
NEWS, EDITORIALS, REFERENCE
Current Directory Pointers CMD HD
Back in 1986, Berkeley Softworks released the first version of GEOS v1.0 for the Commodore 64. At that time the 1541 disk drive reigned supreme as the storage device for the C64. The 1571 was released the year before GEOS, but the 1541 was and forever remained far more popular.
The 1541 and 1571 were very low capacity 5.25" floppy disk drives. The 1541 could only access one side of the disk at a time offering only 664 blocks of storage (~170KB.) You could flip the disk upside down, but the other side had to be formatted with an independent file system. The 1571 could read both sides of the disk and integrate them into a single pool of storage, doubling the capacity of one file system to a whopping ~340KB.
With a storage capacity that is so low, there isn't much point in the file system supporting subdirectories. Organization of files can be done much more practically per disk. Then you can file your disks into different disk cases with little labeled dividers between them.

Suffice it to say, the file system on a 1541 or 1571 disk is very simple. But GEOS is a sophisticated system offering some quite advanced features. For example, applications which appear as a single file in the directory sport a custom icon, a version number, and blocks of text for comments and an author and copyright info. The application's code segment can be even more complex, with different content streams that can be accessed and loaded independently.
Original CBM file systems also don't support seeking, but they did grant raw access to 256-byte blocks of data referenced by track and sector number. The operating system reads in the directory block by block, starting at the track and sector where the directory is known to start. Then unused bytes in the raw directory entry are used to store some extra information, such as a special GEOS file type byte, a date/timestamp, and a file structure.
From there, the structure of the file could be non-linear. What does that mean, non-linear? In a regular file, like a PRG or a SEQ-type file, the directory entry has a track and sector pointer which is an address for where on the disk to find the first block of the file's data. In that block, the first two bytes are used to point to the track and sector where the next block is found. This chain is linear; Directory Entry → First Block → Second Block → Third Block… and so on until the last block. The last block uses the first two bytes to indicate that this is the last block, and how much of this last block is used.
This linear block-to-block linking structure is supported by the CBM DOS stored in ROM in the drive. You can just open a file, write a bunch of data to that file, and then close it. Inside the drive it's filling a block with data, and when the block fills up it allocates a new block, links it to the chain, and starts filling data into that block. All of this work is supported by the drive's DOS itself.
However, because these original disk drives give software direct access to raw blocks of data, it is not necessary to be limited only by what the drive's own DOS can do.
GEOS uses a block of a file (usually the second linear block) like a mini directory. The block is 256 bytes big, and each pair of bytes can be used to point to the starting block of a linear chain of blocks. So the file as a whole is not linear but can have up to 127 sub-files. It goes:
Directory Entry → Info Block → Block of Pointers
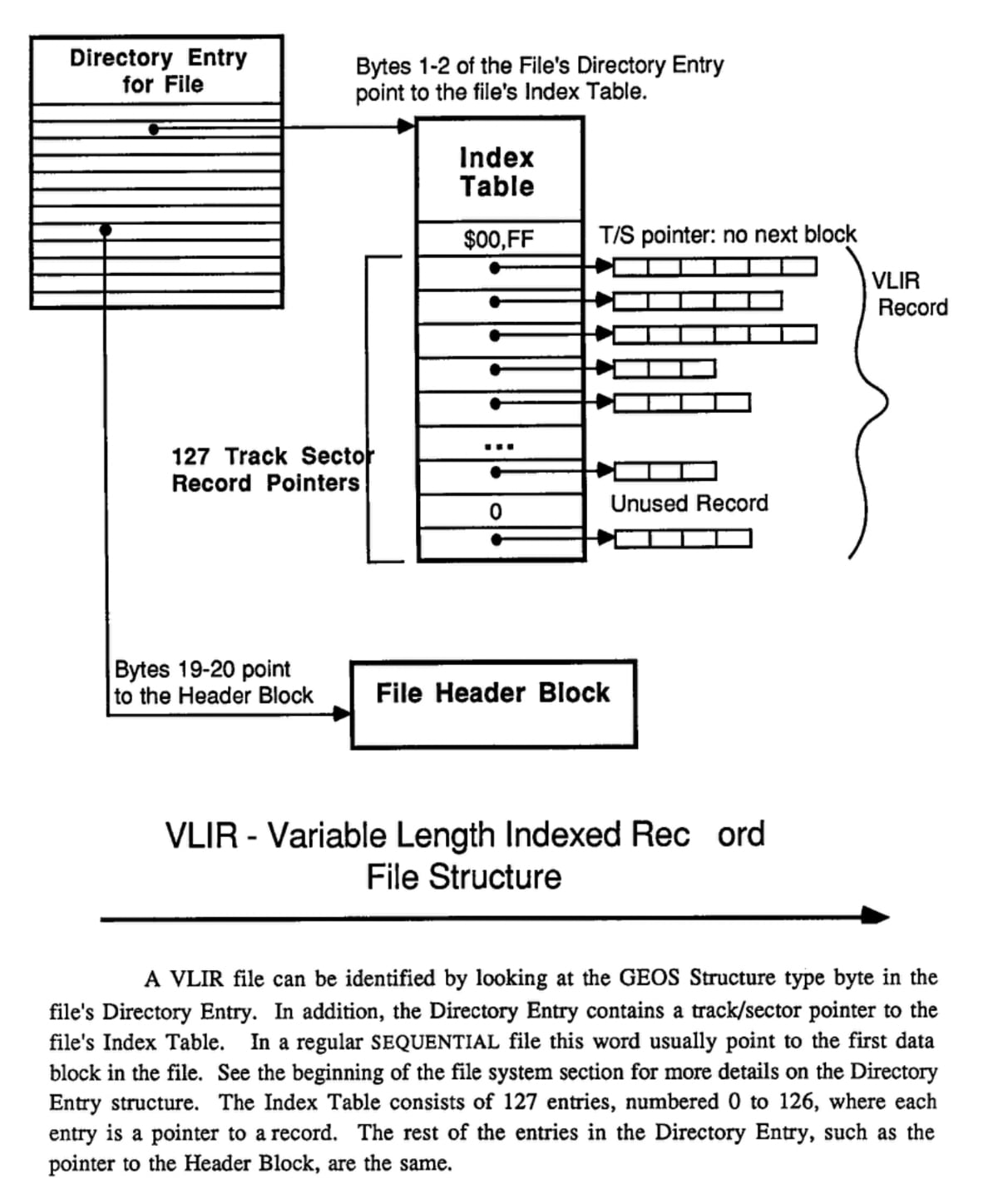
VLIR Format - GEOS Programmer's Reference Guide
The upside is that a disk which doesn't support subdirectories can have a file where the file maintains up to 127 mini files or records within it. Each of those subfiles is a linear chain of blocks, so they're not limited to a single record length the way relative files are.
There are of course downsides to this as well. For one, you must never validate a 1541 or 1571 (or 1581) disk using the built-in DOS's validate command or it will break all of your GEOS files stored therein. Why does it do this? The validate routine is a kind of block usage cleanup procedure. It starts with a clean BAM slate, a block allocation map that is like it would be if the disk were freshly formatted. Then it meticulously walks the directory blocks, marking as used in the BAM the sector that each directory block occupies. And for each file encountered in the directory, it follows each of their data chains to the end and records in the BAM all the sectors used by all the files as it goes. When it's finished, assuming it doesn't encounter any unrecoverable errors such as broken or invalid link pointers, it writes out the clean new BAM. The validate routine doesn't have any concept of the special GEOS non-linear format though, and so it effectively deallocates all the blocks that were manually allocated to create the non-linear files. Ooops.
GEOS comes with its own validate feature that can be used to safely validate and repair a disk with GEOS files on it. And the DOS built into a CMD HD, FD-2000/4000 and RAMLink know how to safely validate a partition with GEOS files in them.
CMD HD, FD-2000/4000 and RAMLink
In the 1990s, Creative Micro Designs Inc. first released the CMD HD, followed by the CMD FD-2000, the FD-4000 and the RAMLink.
These devices have support for native-mode partitions that are up to 16MB in size. Why only 16MB? Actually it has a lot to do with what we've just learned about 1541, 1571 and 1581 disks. It was important to CMD for their devices to remain compatible with GEOS, since GEOS was the most advanced operating system environment, and by far the most productive and the most successful, that the Commodore 64 had at its disposal, at that time. And GEOS needs to be able to access blocks by track and sector.
Let's focus on the CMD HD, but the FD-2000/4000 and RAMLink follow a pretty similar logical layout.
Blocks are still 256 bytes, and blocks are still chained together using the first two bytes to point to the track and sector of the next block. The main difference is that tracks are real things on a disk; rings around the spinning medium that the head can step to in discrete hops. Each track is divided into sectors, but since tracks close to the spindle are shorter they have fewer sectors than the longer tracks at the outside of the disk. Partitions on the CMD HD are carved out of storage on a much more sophisticated medium, a SCSI hard drive.
On a CMD HD's native partition, all tracks have the maximum of 256 sectors, and you can choose how big to make the partition by varying the number of tracks it has. 256 tracks times 256 sectors = 65,536 sectors. It's actually a little bit less than this for technical reasons, but it's not more than this. 65,536 sectors times 256 bytes per sector = 16,777,216 bytes = 16MB. This is why a native mode partition maxes out at just under 16 megabytes.
A storage device doesn't have to limit itself to this, for example the IDE64 has a custom file system, 512 byte blocks and supports huge multi-gigabyte partitions. But, at the expensive of compatibility with the likes of GEOS and GoDot, etc., because under-the-hood it stores the data in a very different way.


Even a 16MB partition is pretty big for a Commodore 64. It's much too big to limit the files to being stored in a single root directory. To accommodate the larger storage capacity, CMD's HD DOS introduced support for subdirectories. There are special commands for creating and removing a subdirectory. They can be renamed using the standard rename command for files. You cannot scratch a subdirectory or open it like you can open a file. There is a special command to remove a directory, if it's empty, and there is a command to change into the subdirectory.
So how does that work? Let's say you're in the root directory. The device knows the fixed track and sector address of the starting block of the root directory. A directory actually starts with a header block. The header block is mostly empty, but on a 1541 disk it holds the title of the disk, which you see when you load and list the directory. The header block points to the first proper directory block, and it was probably done this way so that every proper directory block is structured exactly the same: 8 directory entries, 32 bytes each. The first 2 bytes of every entry are null, because the first 2 bytes of the first directory entry are used for the track and sector pointers to the next block, and it's easier from a programming standpoint if data structures are consistent, even at the expense of a bit of wasted space.
To find a file by name, or pattern, HD DOS reads in the directory's header block, that points to the first directory block, it reads that into memory (the drive's own memory, not the computer's.) It scans through the 8 directory entries of that block looking for a match. If it doesn't find one, it uses the pointer at the start of this block to read in the next directory block. And repeats until it finds the matching directory entry, or it reaches the end of the directory chain and generates a file not found error. Each 32-byte directory entry has the file's name, some other information such as its CBM file type, plus the track and sector pointer for the first data block of the file.
Subdirectories are like special files. They have a 16-character "filename" and a type of DIR rather than PRG or SEQ, et al. When you create a new regular file it always gets one data block assigned to it. One new block is allocated in the BAM, the block is initialized to indicate that it's the last block and has no data in it. Then the directory entry for the new file is created and its track and sector numbers are pointed at the newly allocated data block. Subdirectories are quite similar. When you create a new subdirectory, and you supply a name, it allocates a new block which it initializes like any directory header block. The name of the directory is written into this header. It then allocates a first directory block, which it initializes as the last block with no entries in it. All the pointers are set up. The directory entry points to the new header block, the header block points to the new first (empty) directory block. And all the newly used sectors are marked as allocated in the BAM.
Navigating the file system with pointers
We know what happens when you try to open a file by name. The first thing it does is load in the directory header block, and then it follows the pointers through the chain of directory blocks, looking for your filename by string and pattern matching against one directory entry after the next. But how does it find the directory header block?
On a 1541 that would be easy. The header block is always at Track 18, Sector 0. And the first directory entry block is always at Track 18, Sector 1. This can be hardcoded into the 1541's DOS ROM. In a CMD HD's native partition, the root directory header block is found at Track 1, Sector 1, and the first two bytes point to the first directory block.
But what happens when you navigate into a subdirectory, by name? It starts with the current directory, searches for the directory entry that matches that name, it should confirm that it is actually of type DIR (although in my experience there is a bug here and it doesn't confirm that.) Then it pulls the track and sector pointer from that directory entry and sets it as the track and sector of the current directory.
Interestingly, the drive does not retain the "path" as a string to where you are in the subdirectory tree. And rather than have a hardcoded track and sector number for where the root directory is found, it has variables in memory that point to the the track and sector where the current directory is found. After that, everything is relative to that start point. If you try to open a file by name, it follows exactly the same steps, except instead of starting at Track 1, Sector 1, it starts at whatever block the current directory pointers point to. In a sense, the drive does not really know that it is in a subdirectory, and if it is in a subdirectory it definitely does not know if it's 2 subdirectories deep or 10 subdirectories deep.
The question then arises, how does it go up a directory? There are actually two ways to go up from wherever you are in the subdirectory tree. You can go up one level to the immediate parent directory or you can jump back all the way to the root directory. The following commands are used to do this:
These commands are sent to the command channel, channel 15: cd← cd//
The directory header block has a track and sector pointer to the root directory's
header block (although in practice this is always 1,1.) And it has a pointer to the
header block of the parent directory. That's actually pretty straightforward. You
send the command cd← and we know what it's going to do. It uses
the track and sector pointer to the current directory's header block and loads this
into the drives memory. It reads the parent directory track and sector pointer
from this header block, and writes them into the memory variables for the current
directory. Done.
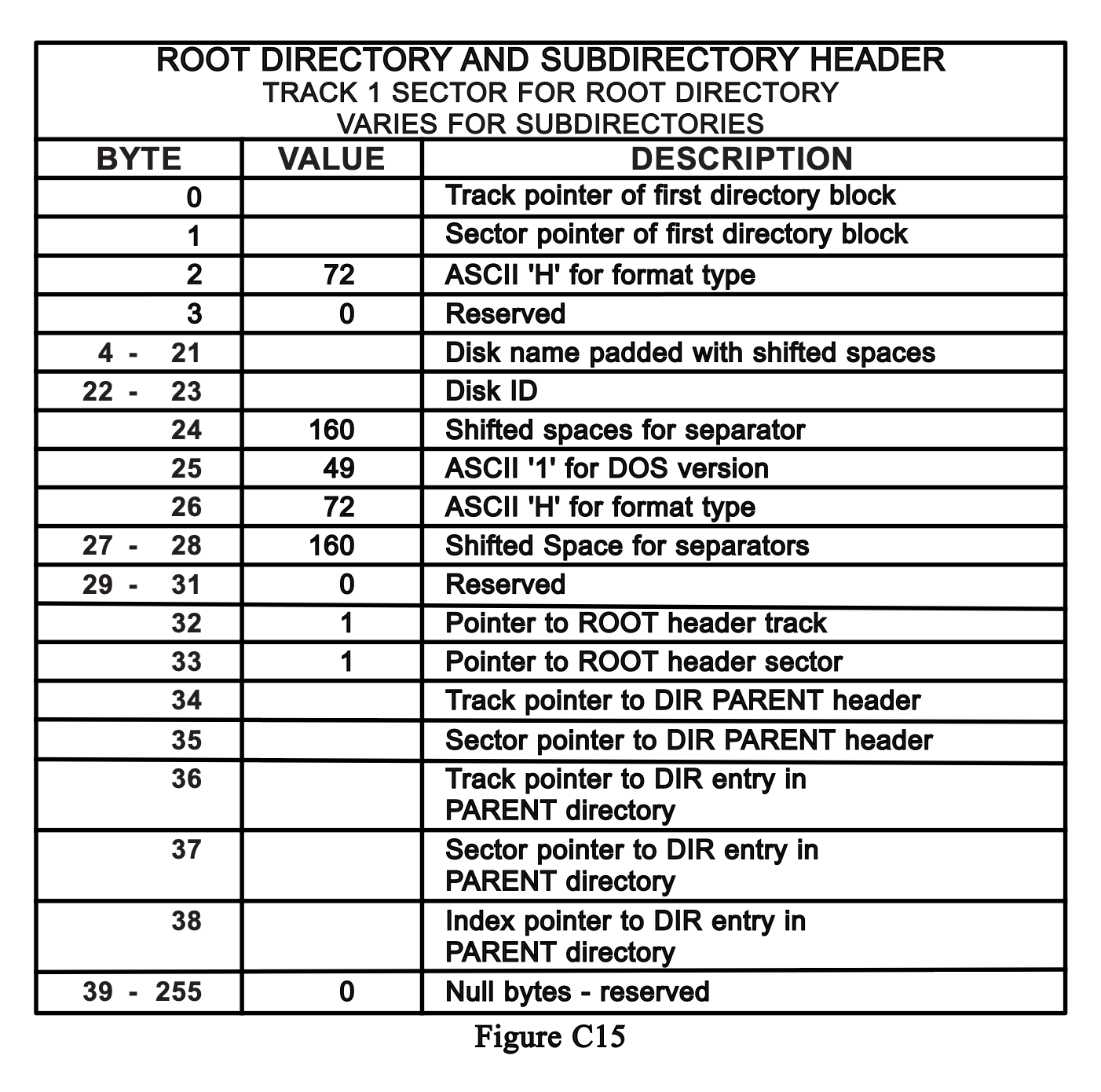
Directory Header Block
You can see that it is technically possible for the drive to know that it's in a
subdirectory. If the current directory's track and sector pointers are not 1,1, then
it must be in a subdirectory. Further, if you load the current directory's header block
and the parent directory pointer is 1,1, then you must be in a subdirectory that is
just one level deep. Unless you're already in the root directory. The
root directory's parent directory pointer probably points to 1,1, too. It points
to itself, so that even when you're in the root directory you can issue the command
cd←, it follows the same procedure, and you don't get an error.
Nothing changes, you're still in the root directory, but you don't get an error
and it doesn't need to handle the root directory as a special case.
If on the other hand you are 4 subdirectories deep, the current directory pointers are not 1,1, so it knows you're not in the root. If it loads the current directory's header block, the parent directory pointer is also not 1,1. So it knows you're not just one level deep, but without an algorithm and iterative or recursive processing it does not know how deep in the subdirectory tree you are. That is fascinating to me.

How does C64 OS navigate the directory tree?
C64 OS has been designed to be device agnostic. It sends DOS commands that are common between the devices, it does not access raw blocks addressed by track and sector. The main reason for this is because newer devices are not build on 256-byte blocks with single track and sector pointer bytes. IDE64, SD2IEC and soon the SoftwareIEC feature on Ultimate64 and Ultimate II+, they use widely varying underlying file systems. So does VICEFS, Pi1541, Meatloaf and others.
How does C64 OS navigate the file system of these different devices? C64 OS uses file reference structures. A file reference holds the device number, the partition number, and the full textual path from the root directory. The path is limited to 232 characters, so C64 OS is limited by the length of the path. If subdirectory names are maximally short (1 character), 232 bytes can hold a path that's 232 - 2 (for the initial //), divided by 2 (1 character name plus trailing slash), equals 115 subdirectories deep. Or, if names are maximally long (16 characters), (232 - 2) / 17 = ~13. If you average these, assuming some subdirectory names are short and some are long, it supports around 28 levels deep. This is much more than deep enough for a Commodore 64.
| Constant | Offset | Size | Notes |
|---|---|---|---|
| frefdev | 0 | 1 | Device # (1 to 30) |
| frefpart | 1 | 1 | Partition # (1 to 255) |
| freflfn | 2 | 1 | Logical File Number. 0 = File not open. |
| frefblks | 3 | 2 | 16-bit (little endian) block size of the file on disk. |
| frefname | 5 | 17 | 16 character filename, null terminated. |
| frefpath | 22 | 234 | Absolute path from root of partition, null terminated. |
When you navigate the file system, in File Manager, say, if you click the path bar
to go up 3 subdirectories, it performs string manipulation to remove the last 3
path parts in the file reference, and then sends a change directory command with
the full remaining path from the root. Whenever C64 OS software is going to
perform atomic file operations,
that is, it will take command of a drive and perform a series of file operations
before returning control to the OS (and possibly other processes), it uses the
KERNAL call finit on a file reference. This configures the correct
drive's own context for this partition and path. After that file operations relative
to this context can safely be performed.
There may be some inefficiencies to this method, but it is beautifully device
agnostic. It also allows processes to change the current context of the device,
and the different processes don't lose track of where they are. Every process must
assume that the drive's current context is wrong, because something else probably
changed it. Therefore, before performing file operations that are relative to a
specific partition and path, it should begin with a call to finit.
How to find a directory entry
We have an interesting problem now.
Suppose we want to write a C64 OS application that analyzes a GEOS file. This is not an unreasonable task. First, a non-sequential GEOS file cannot be stored naturally on an IDE64 or an SD2IEC, or VICEFS etc. The typical solution for these other devices, SD2IEC in particular, is to mount a disk image in which simple 256-byte track and sector addressing makes sense.
Laying aside other device families, again for simplicity, let's stick with the CMD HD. Let's just say our C64 OS application will recognize that the device being accessed is a CMD HD and can therefore use CMD HD specific DOS commands, track and sector layouts, etc. In this limited-implementation thought experiment, if it's not a CMD HD it could just report to the user that this device type is not supported.
How do we actually access information about a GEOS file? Part of the information is in the file's info block, but there is also information in the file's directory entry itself. For example, offset $15 in the directory entry indicates if the file has a sequential or VLIR (non-sequential) structure. And offset $16 is a GEOS type byte indicating one of these types:
0 Non-GEOS file. 1 BASIC Program. 2 Assembly program. 3 Data file. 4 System file. 5 Desk Accessory. 6 Application. 7 Application Data. 8 Font file. 9 Printer driver. 10 Input driver. 11 Disk Device 12 System Boot file 13 Temporary 14 Auto Executing 15 Input 128 ... there may be others.
How do we get that information? We have to load in the raw directory blocks from the current directory. This is what GEOS does, it loads in and parses the directory blocks. But this is also why GEOS can't handle an IDE64 because the structure is just so different that never the twain shall meet.
But in this case, testing for the device type, we can request a directory block from a CMD HD. We can parse through the directory manually. This isn't how File Manager navigates more generally, but in this particular Application we can do that. The problem is, where is the current directory? By track and sector, where does this directory start? In GEOS, (or one of its descendents like Wheels, or I suppose Megapatch) the whole system is always reading in and parsing the directory blocks. And if you navigate into a subdirectory, it has to parse that subdirectory's blocks so it can hang on to the track and sector that were used to get you there in the first place.
We don't have this track and sector number in C64 OS though. What we have is a textual
path. What happens if we're 75 nested subdirectories deep? Sure, this is unlikely,
but it's not impossible, so the software has to be able to handle this situation.
What do we do? Well, one thing that we could do is parse the textual path. Pull the
first path part between the // and the following /. Then
we could start loading and parsing the directory blocks from the root directory and
trying to find the subdirectory whose name matches. Now we've got the track and sector
pointer for that directory header. Then we repeat, parse from the path the next
subdirectory name after the current / up to the next /.
Read in the directory blocks and try to find that.
I don't know about you, but this feels like a HUGE pain. What if there are hundreds of files in each of those directories? A huge pain and a lot of time spent reading data from the drive across the IEC bus and into the computer. Data that you don't even need or want to retain. Is this really our only option?
Current directory pointers
This got me to thinking though. Each partition on a CMD HD remembers what its current directory is. Besides that it's documented as such, how do we know this? How do we prove that this is the case? Well, you can do stuff like this:
switch to partition 2 cp2 change current directory cd//documents/work/2025/ switch to partition 8 cp8 change current directory cd//workspace/temporary/docs/ copy a file between partitions c2:post.txt=8:post.txt
When the copy command is executed, the destination is partition 2, but because no path is specified it will go to the current directory of partition 2. And the source file comes from partition 8. But again, since no path is specified it comes from the current directory of partition 8.
We're currently in partition 8, and it's got pointers to the current directory here, but we're copying a file to partition 2, and conveniently, it knows the current directory in that partition too. But we've already established that it doesn't keep a path string for each partition; unlike C64 OS, the drive itself doesn't keep a path string ever of any kind. Additionally, the copy begins immediately; there isn't a delay as it looks up //documents/, then looks up work/, then looks up 2025/. It starts right away. So the drive must be retaining the current directory track and sector pointers for every partition. It's the only way. But where does it do that?
I couldn't find this anywhere in the documentation. But what I did find was Appendix D, HD Memory Map. This indicates that $8000 to $93FF is reserved for System I/O, Tables & Parameters. The next page has a table called CMD HD Extended Memory Map, and it says that $9000 to $93FF, 4 pages of memory, is for DOS Tables. Very promising!

CMD HD Extended Memory Map
Disk Cracker HD
Let me tell you, Disk Cracker HD is an amazing tool. It comes included on the CMD HD Utilities disk, and we'll take a look at it in a moment.
I knew that you could use Disk Cracker HD to read, edit and write drive sectors, but I didn't realize you can also use it to examine the drive's memory. I've used it many times to sector edit, usually to repair some damage caused by a program that blindly treats the CMD HD like it's a 1541. But because I don't usually have any reason to examine the drive's memory I just didn't notice that it has this ability. It's actually pretty obvious, it's in the menu commands.
What I did instead was write a quick and dirty little program in BASIC to read in some memory from the drive. This is quite easy to do. You open a connection to channel 15. Then send an "M-R" (memory read) command. Following the M-R command you send the start address, two bytes little endian, and a length of bytes to read. You can read from 1 to 256 bytes, where 256 is represented by 0. After sending this command the bytes are returned immediately on the error channel.
So I requested all of page $90xx, and wrote the bytes to $60xx in the C64's main memory. And then repeated loading page $91 and saving to $61 and so on up to page $93 saving to page $63.
All we have to do after that is use a machine language monitor to checkout what is found between $6000 and $63FF in main memory. My preferred machine language monitor can be downloaded from the C64 Software Releases page, and includes a summary of the commands that it supports.
At $6100 and $6200 (so that would be $9100 and $9200 in the CMD HD's memory) I found some very interesting looking numbers.


First, most of the numbers are zero. But in both pages, there are non-zero values at the same offsets: 1, 2 and 7. It is typical in 6502 assembly programming to use two memory pages for two tables to store pointers. One table holds the pointer low bytes and for each low byte the high byte of the pointer is found at the same index in the other table. We're not looking for memory pointers, of course, but track and sector pointers which are conceptually very similar. These numbers could give us:
| Offset | Track | Sector |
|---|---|---|
| $01 | $74 (116) | $11 (17) |
| $02 | $01 (1) | $01 (1) |
| $07 | $01 (1) | $40 (64) |
Or it could give us this:
| Offset | Track | Sector |
|---|---|---|
| $01 | $11 (17) | $74 (116) |
| $02 | $01 (1) | $01 (1) |
| $07 | $40 (64) | $01 (1) |
Going back into Disk Cracker now. You can request tracks and sectors but you have to type them in decimal, so I've converted the hexadecimal to decimal in the parentheses above.
Assuming that the offsets are for partition numbers, then in partition 2 if we load track 1 and sector 1, indeed we get the root directory's header block. Of course we already know that the header block is found at 1,1, but this is confirmed because I had actually changed to partition 2 and left it in the root directory.
In partition 7, if we try to load in track 64, sector 1, it just loads in an unrecognizable garble of data. But if we swap that around and load in track 1, sector 64, look, it's a directory header block! Therefore, above, table 1 is correct and table 2 is not.
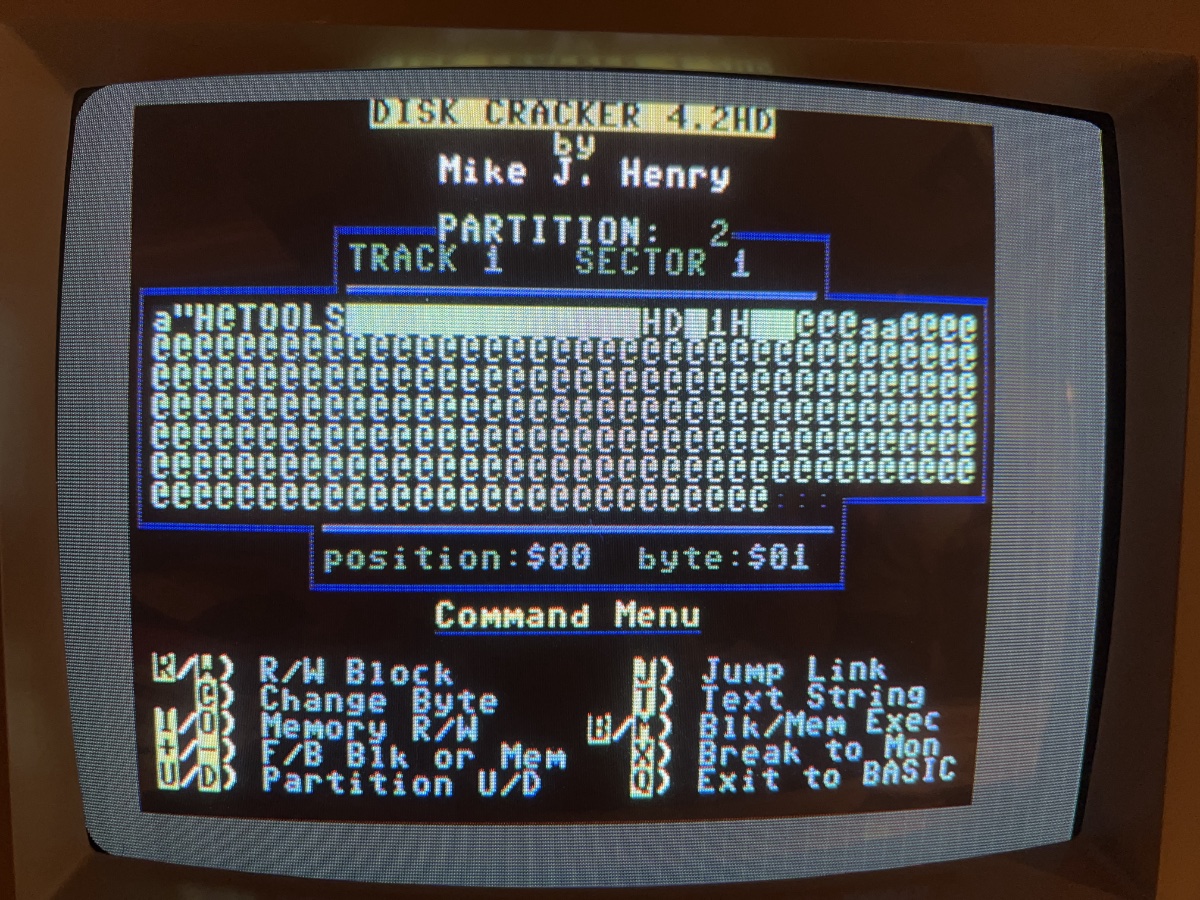
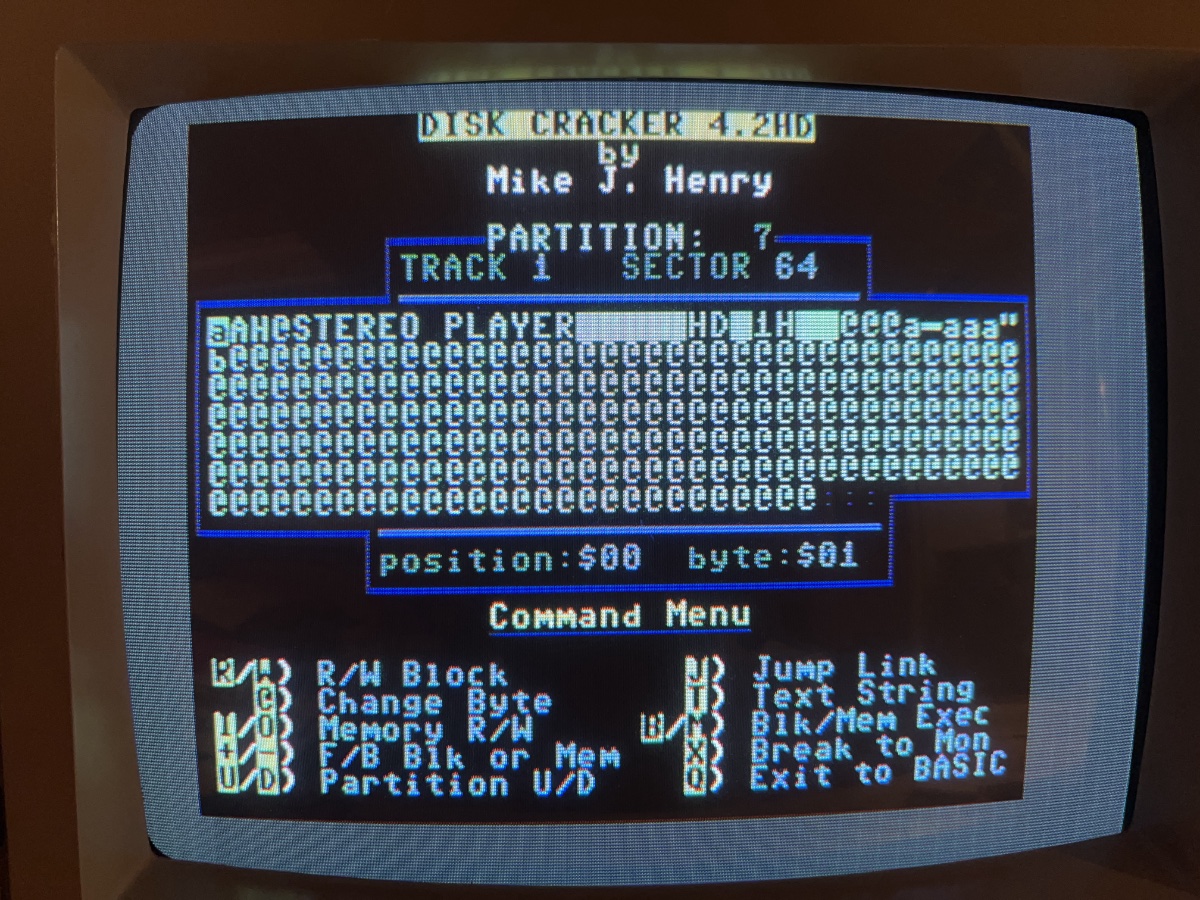
And indeed, I had changed into partition 7, and I'd switched into the Stereo SID player subdirectory and left that as the current directory.
Conclusion and Solution
This was so much fun for me. Not only did I learn something about the CMD HD, but I also found a very clean solution to the problem of finding the current directory. Let's recap how this works.
The CMD HD can have up to 255 partitions, numbered 1 to 255. The 0th partition is a special system partition that you can change into using DOS commands.
The drive's memory pages $91 and $92 are initialized all to zero on power up or hard reset. When you change to a partition the bytes in $91 and $92 at the offset equal to the partition number are checked. If they're currently 0, they have not yet been initialized. For native partitions, these get automatically initialized as 1 and 1, for track 1, sector 1. For emulation type partitions the values in these tables seem to have a slight variation in how they're used, but I'm not going to delve into that in this post.
For those interested, there is another memory page, $82xx, which is used for the Partition Type table. This table can be consulted to determine if a partition is native by checking the type byte at the offset equal to the partition number.
Once the track and sector directory header pointers have been initialized, all relative path accesses to this partition are done by starting at whatever these values are. If you change into a subdirectory, the track and sector numbers for the subdirectory header are found by looking through the current directory, and are written into the tables at $91xx and $92xx. And that's it. Now, all path relative operations are done the same but start from this subdirectory.
The two tables are enough to hold a current directory track and sector pointer for every partition. And looking up where to start for path operations takes exactly, precisely, the same code and time whether its in the root directory, an immediate subdirectory or 50 nested subdirectories deep. Very cool.

And from inside C64 OS, if we have a file reference with a long winding path, all
we have to do is call finit on the file reference to initialize the
partition's current directory pointers. Then we can perform an M-R command starting at
low byte equal to the partition number and high byte equal to $91, loading 1 byte, to
get the sector number. Then issue another M-R command starting at the low byte
equal to the partition number and the high byte equal to $92, loading 1 byte, to
get the track number. From this track and sector, we can load in and parse the
directory sectors of the current directory, just as easily as if it were the single
directory of a 1541 disk.
Do you like what you see?
You've just read one of my high-quality, long-form, weblog posts, for free! First, thank you for your interest, it makes producing this content feel worthwhile. I love to hear your input and feedback in the forums below. And I do my best to answer every question.
I'm creating C64 OS and documenting my progress along the way, to give something to you and contribute to the Commodore community. Please consider purchasing one of the items I am currently offering or making a small donation, to help me continue to bring you updates, in-depth technical discussions and programming reference. Your generous support is greatly appreciated.
Greg Naçu — C64OS.com


